I am working on an Oracle 19c database running on a RHEL 7 VM. I have been trying to roll back this patch:
Patch 30763851 IMPDP 11.2 TO 18C OR HIGHER HITS ORA-904 WHEN TABLES HAVE EXTENDED STATISTICSI have it sitting on top of 19.5
Database Release Update: 19.5.0.0.191015 (30125133)The Opatch rollback command ran fine, but Datapatch threw these errors:
[2025-10-22 18:50:15] -> Error at line 11329: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11331: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11333: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11335: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11337: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11339: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11341: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11343: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_OPQTYPE_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11355: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_P2TPARTCOL_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11357: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_P2TPARTCOL_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11363: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_SP2TPARTCOL_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11365: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_SP2TPARTCOL_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11381: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11383: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11385: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11387: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11389: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11391: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11393: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11395: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11397: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_P2TCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11399: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_P2TCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11401: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_SP2TCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11403: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_SP2TCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11405: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11407: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_COLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11409: script rdbms/admin/dpload.sql
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"
[2025-10-22 18:50:15] -> Error at line 11411: script rdbms/admin/dpload.sql
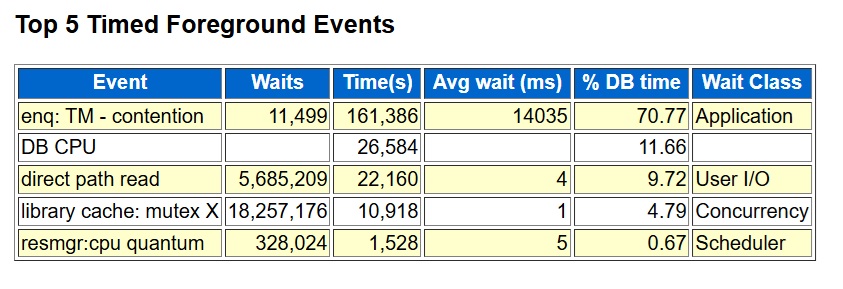
[2025-10-22 18:50:15] - ORA-04063: view "SYS.KU$_PCOLUMN_VIEW" has errors"I checked DBA_OBJECTS, and all the SYS objects are VALID. I tried querying one of the views and it worked fine. So, I went to My Oracle Support, our Oracle database support site, and searched for ORA-04063 and one of the view names and found nothing. A Google search also came up empty. I tried just ignoring it but that didn’t work. My whole goal in doing this was to apply the October 2025 patches that just came out this week. But because the SQL patch registry indicated that patch 30763851 rolled back with errors, every time I applied a new patch it would try to roll 30763851 back first and error again. Here is what DBA_REGISTRY_SQLPATCH looked like after two failed rollback attempts:
INSTALL_ID PATCH_ID PATCH_TYPE ACTION STATUS
---------- ---------- ---------- --------------- --------------
1 30125133 RU APPLY SUCCESS
2 30763851 INTERIM APPLY SUCCESS
3 30763851 INTERIM ROLLBACK WITH ERRORS
3 30763851 INTERIM ROLLBACK WITH ERRORS
4 30763851 INTERIM ROLLBACK WITH ERRORS
4 30763851 INTERIM ROLLBACK WITH ERRORS Each rollback attempt tried twice so I have four failures with two rollback attempts.
I opened a case with Oracle support just in case this was a known issue that wasn’t available for me to find on my own. Sometimes that happens. But while waiting on Oracle I kept trying to fix it myself.
The errors refer to $ORACLE_HOME/rdbms/admin/dpload.sql which I think reloads datapump after some change. It runs catmetviews.sql and catmetviews_mig.sql which have the CREATE VIEW statements for the views getting errors, like SYS.KU$_OPQTYPE_VIEW. But the code in catmetviews_mig.sql wasn’t straightforward. I imagined running some sort of trace to see why the script was throwing the ORA-04063 errors, but I never had to take it that far.
At first all this stressed me out. I thought, “I can’t back out this patch. I will never be able to patch this database to a current patch level.” Then I chilled out and realized that if it was a problem with Oracle’s code, they had to help me back out 30763851. But it might take some time to work through an SR with Oracle.
But what if it wasn’t an issue with Oracle’s code but something weird in our environment? I didn’t think it indicated a real problem, but there were some weird messages coming out that I am used to seeing. They were from triggers that come with an auditing tool called DB Protect. They were throwing messages like this:
[SYS.SENSOR_DDL_TRIGGER_A] Caught a standard exception: aliasId=100327, error=-29260, message="ORA-29260: network error: TNS:no listener"We are used to seeing these errors when we do DDL but prior to this it didn’t cause any actual problems. We had already decommisioned the DB Protect tool but had not cleaned up the triggers. Dropping SYS.SENSOR_DDL_TRIGGER_A eliminated the ORA-04063 errors.
Probably no one will ever encounter this same issue, but I thought I would document it. If you have the same symptoms and you are not using DB Protect any more, do these commands:
DROP TRIGGER SYS.SENSOR_DDL_TRIGGER_A;
DROP TRIGGER SYS.SENSOR_DDL_TRIGGER_B;I think the A trigger was the problem, but we don’t need either one.
Anyway, this post is just so someone who searches for ORA-04063 and one of the views will find this information and drop the triggers if they have them. It’s a long shot but might as well document it for posterity and for me.
Bobby