Sunday four batch jobs that normally run in an hour had been stuck for 3 hours and had not completed the first unit of work out of many. Earlier in the day the on call DBA had applied a SQL Profile and cancelled the jobs and rerun them but it did not help. We picked a different SQL Profile, killed the jobs, and the jobs ran normally. How did we figure out the right plan to use for a SQL Profile?
The main clue came from the output of my sqlstat.sql script:
The good plan seemed to be 2367956558. EXECUTIONS_DELTA = 1 means that the SQL finished in that hour. Elapsed Average ms of 45177.105 was 45 seconds. 19790.066 was 19 seconds.
PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA Elapsed Average ms
--------------- ------------------------- ---------------- ------------------
2367956558 20-APR-25 01.00.23.638 AM 1 45177.105
2367956558 20-APR-25 03.00.29.921 AM 1 19790.066
The other plans 2166514251 and 3151484146 seemed to have executions that spanned multiple hours. For example, the first 2166514251 line had EXECUTIONS_DELTA = 0 which means it didn’t finish in that hour. Plus, the elapsed time of 8995202.39 ms = 8995 seconds = 2.5 hours suggests that it was running in parallel, probably for the entire hour.
PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA Elapsed Average ms
--------------- ------------------------- ---------------- ------------------
2166514251 20-APR-25 01.00.23.638 AM 0 8995202.39
So, it seems clear that 2367956558 is the best plan.
I could say a lot more about this incident, but I wanted to focus on the sqlstat.sql output. The values of EXECUTIONS_DELTA and Elapsed Average ms are keys to identifying plans with the best behavior.
Everyone who has heard the old saying “a picture is worth a thousand words” appreciates its simple wisdom. With Oracle databases you have situations where a graph of the output of a SQL query is easier to understand than the standard text output. It’s helpful to have a simple way to graph Oracle data, and Python has widely used libraries that make it easy.
This post describes a Python script that graphs data from an Oracle database using the Matplotlib graphics library. The script uses three widely used Python libraries: cx_Oracle, NumPy, and Matplotlib. This post provides a simple and easily understood example that can be reused whenever someone needs to graph Oracle data. It is written as a straight-line program without any functions or error handling to keep it as short and readable as possible. It demonstrates the pattern of cx_Oracle -> NumPy -> Matplotlib and the use of Matplotlib’s object-oriented approach.
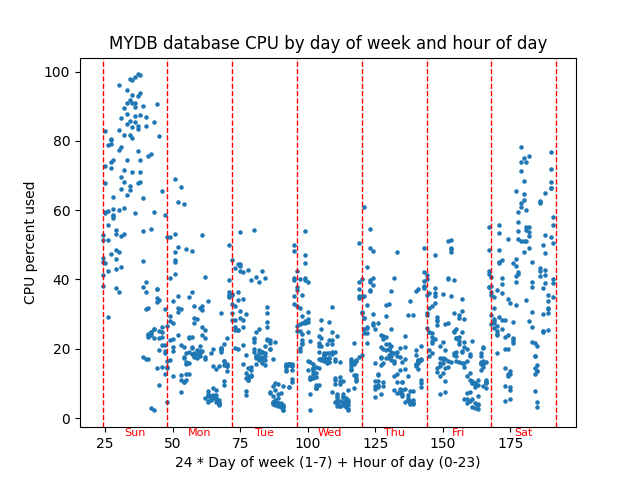
Here is an example graph:
The script graphs database server percent CPU used versus a combination of the day of week and the hour of the day to see if there is any pattern of CPU usage throughout a typical week. This graph has about 6 weeks of hourly AWR snapshots graphed in a scatter plot with CPU percentage on the Y axis and (24 * day of week) + hour of day as the X axis. You could think of the X axis as the hour of the week. This graph might be helpful in performance tuning because it shows whether CPU usage follows a weekly pattern.
Here is the current version of the script: scatter.py.
The script has three main parts which correspond to the three non-internal Python libraries that I use:
cx_Oracle – Query the CPU data from an Oracle database
NumPy – Massage query data to get it ready to be graphed
These libraries all have lots of great documentation, but Matplotlib’s documentation is confusing at first. At least it was for me. Here are three useful links:
Quick start – This is a great overview. The picture of the “Parts of a Figure” is helpful. I don’t know if earlier versions of Matplotlib had this picture.
Axes – This is a nice list of all the methods of an Axes object. Most of the code in the example script involves calling these methods. I have trouble finding these methods using a Google search, so I bookmarked this link.
Figure – The example script does not call any Figure object methods, but I wanted to document where to find them here. I bookmarked this URL as well as the Axes one because a Matplotlib graph is composed of at least one Figure and Axes object. With the Quick start link and these two lists of methods you have all you need to write Matplotlib scripts.
cx_Oracle
The query for this graph pulls operating system CPU metrics from the DBA_HIST_OSSTAT view and uses them to calculate the percent of the time the CPU is busy. It is made of two subqueries in a with statement and the final main query.
with
myoscpu as
(select
busy_v.SNAP_ID,
busy_v.VALUE BUSY_TIME,
idle_v.VALUE IDLE_TIME
from
DBA_HIST_OSSTAT busy_v,
DBA_HIST_OSSTAT idle_v
where
busy_v.SNAP_ID = idle_v.SNAP_ID AND
busy_v.DBID = idle_v.DBID AND
busy_v.INSTANCE_NUMBER = idle_v.INSTANCE_NUMBER AND
busy_v.STAT_NAME = 'BUSY_TIME' AND
idle_v.STAT_NAME = 'IDLE_TIME'),
The myoscpu subquery pulls the CPU busy and idle times from the view along with the snapshot id. I think these are totals since the database last came up, so you have to take the difference between their values at two different points in time to get the CPU usage for that time.
myoscpudiff as
(select
after.SNAP_ID,
(after.BUSY_TIME - before.BUSY_TIME) BUSY_TIME,
(after.IDLE_TIME - before.IDLE_TIME) IDLE_TIME
from
myoscpu before,
myoscpu after
where before.SNAP_ID + 1 = after.SNAP_ID
order by before.SNAP_ID)
The myoscpudiff subquery gets the change in busy and idle time between two snapshots. It is built on myoscpu. My assumption is that the snapshots are an hour apart which is the case on the databases I work with.
select
to_number(to_char(sn.END_INTERVAL_TIME,'D')) day_of_week,
to_number(to_char(sn.END_INTERVAL_TIME,'HH24')) hour_of_day,
100*BUSY_TIME/(BUSY_TIME+IDLE_TIME) pct_busy
from
myoscpudiff my,
DBA_HIST_SNAPSHOT sn
where
my.SNAP_ID = sn.SNAP_ID
order by my.SNAP_ID
The final query builds on myoscpudiff to give you the day of the week which ranges from 1 to 7 which is Sunday to Saturday, the hour of the day which ranges from 0 to 23, and the cpu percent busy which ranges from 0 to 100.
import cx_Oracle
...
# run query retrieve all rows
connect_string = username+'/'+password+'@'+database
con = cx_Oracle.connect(connect_string)
cur = con.cursor()
cur.execute(query)
# returned is a list of tuples
# with int and float columns
# day of week,hour of day, and cpu percent
returned = cur.fetchall()
...
cur.close()
con.close()
The cx_Oracle calls are simple database functions. You connect to the database, get a cursor, execute the query and then fetch all the returned rows. Lastly you close the cursor and connection.
print("Data type of returned rows and one row")
print(type(returned))
print(type(returned[0]))
print("Length of list and tuple")
print(len(returned))
print(len(returned[0]))
print("Data types of day of week, hour of day, and cpu percent")
print(type(returned[0][0]))
print(type(returned[0][1]))
print(type(returned[0][2]))
I put in these print statements to show what the data that is returned from fetchall() is like. I want to compare this later to NumPy’s version of the same data. Here is the output:
Data type of returned rows and one row
<class 'list'>
<class 'tuple'>
Length of list and tuple
1024
3
Data types of day of week, hour of day, and cpu percent
<class 'int'>
<class 'int'>
<class 'float'>
The data returned by fetchall() is a regular Python list and each element of that list is a standard Python tuple. The list is 1024 elements long because I have that many snapshots. I have 6 weeks of hourly snapshots. Should be about 6*7*24 = 1008. The tuples have three elements, and they are normal Python number types – int and float. So, cx_Oracle returns database data in standard Python data types – list, tuple, int, float.
So, we are done with cx_Oracle. We pulled in the database metric that we want to graph versus day and hour and now we need to get it ready to put into Matplotlib.
NumPy
NumPy can do efficient manipulation of arrays of data. The main NumPy type, a ndarray, is a multi-dimensional array and there is a lot of things you can do with your data once it is in an ndarray. You could do the equivalent with Python lists and for loops but a NumPy ndarray is much faster with large amounts of data.
import numpy as np
...
# change into numpy array and switch columns
# and rows so there are three rows and many columns
# instead of many rows and three columns
dataarray = np.array(returned).transpose()
# dataarray[0] is day of week
# dataarray[1] is hour of day
# dataarray[2] is cpu percent
The function np.array() converts the list of tuples into a ndarray. The function transpose() switches the rows and columns so we now have 3 rows of data that are 1024 columns long whereas before we had 1024 list elements with size 3 tuples.
I added print statements to show the new types and numbers.
print("Shape of numpy array after converting returned data and transposing rows and columns")
print(dataarray.shape)
print("Data type of transposed and converted database data and of the first row of that data")
print(type(dataarray))
print(type(dataarray[0]))
print("Data type of the first element of each of the three transposed rows.")
print(type(dataarray[0][0]))
print(type(dataarray[1][0]))
print(type(dataarray[2][0]))
Here is its output:
Shape of numpy array after converting returned data and transposing rows and columns
(3, 1024)
Data type of transposed and converted database data and of the first row of that data
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
Data type of the first element of each of the three transposed rows.
<class 'numpy.float64'>
<class 'numpy.float64'>
<class 'numpy.float64'>
The shape of a ndarray shows the size of each of its dimensions. In this case it is 3 rows 1024 columns as I said. Note that the overall dataarray is a ndarray and any given row is also. So, list and tuple types are replaced by ndarray types. Also, NumPy has its own number types such as numpy.float64 instead of the built in int and float.
Now that our CPU data is in a NumPy array we can easly massage it to the form needed to plot points on our graph.
# do 24 * day of week + hour of day as x axis
xarray = (dataarray[0] * 24) + dataarray[1]
# pull cpu percentage into its own array
yarray = dataarray[2]
My idea for the graph is to combine the day of week and hour of day into the x axis by multiplying day of week by 24 and adding hour of the day to basically get the hours of the week from Sunday midnight to Saturday 11 pm or something like that. The nice thing about NumPy is that you can multiply 24 by the entire row of days of the week and add the entire row of hour of the day all in one statement. xarray is calculated in one line rather than writing a loop and it is done efficiently.
Here are some print statements and their output:
print("Shape of numpy x and y arrays")
print(xarray.shape)
print(yarray.shape)
Shape of numpy x and y arrays
(1024,)
(1024,)
Now we have two length 1024 ndarrays representing the x and y values of the points that we want to plot.
So, we have used NumPy to get the data that we pulled from our Oracle database using cx_Oracle into a form that is ready to be graphed. Matplotlib works closely with NumPy and NumPy has some nice features for manipulating arrays of numbers.
Matplotlib
Now we get to the main thing I want to talk about, which is Matplotlib. Hopefully this is a clean and straightforward example of its use.
import matplotlib.pyplot as plt
...
# get figure and axes
fig, ax = plt.subplots()
First step is to create a figure and axes. A figure is essentially the entire window, and an axes object is an x and y axis that you can graph on. You can have multiple axes on a figure, but for a simple graph like this, you have one figure, and one axes.
# point_size is size of points on the graph
point_size = 5.0
...
# graph the points setting them all to one size
ax.scatter(xarray, yarray, s=point_size)
This actually graphs the points. A scatter plot just puts a circle (or other shape) at the x and y coordinates in the two arrays. I set all points to a certain size and figured out what size circle would look best by trying different values. Note that scatter() is a method of the Axes type object ax.
# add title
ax.set_title(database+" database CPU by day of week and hour of day")
# label the x and y axes
ax.set_xlabel("24 * Day of week (1-7) + Hour of day (0-23)")
ax.set_ylabel("CPU percent used")
More methods on ax. Sets title on top center of graph. Puts labels that describe the x axis and the y axis.
# add vertical red lines for days
for day_of_week in range(8):
ax.axvline(x=(day_of_week+1)*24, color='red', linestyle='--',linewidth=1.0)
The previous lines are all I really needed to make the graph. But then I thought about making it more readable. As I said before the X axis is basically the hour of the week ranging from 24 to 191. But I thought some red lines marking the beginning and end of each day would make it more readable. This puts 8 lines at locations 24, 48,…,192. I set the linewidth to 1.0 and used the dashes line style to try to keep it from covering up the points. I think axvline means vertical line on Axes object.
# Calculate the y-coordinate for day names
# It should be a fraction of the range between the minimum and maximum Y values
# positioned below the lower bound of the graph.
# The minimum and maximum CPU varies depending on the load on the queried database.
lower_bound = ax.get_ylim()[0]
upper_bound = ax.get_ylim()[1]
yrange = upper_bound - lower_bound
fraction = .025
y_coord = lower_bound - (fraction * yrange)
xloc = 36
for day in ['Sun','Mon','Tue','Wed','Thu','Fri','Sat']:
ax.text(xloc, y_coord, day, fontsize=8, color='red', ha='center',fontweight='ultralight')
xloc += 24
I kept messing with the script to try to make it better. I didn’t want to make it too complicated because I wanted to use it as an example in a blog post. But then again, this code shows some of the kinds of details that you can get into. The text() method of ax just puts some text on the graph. I made it red like the dashed lines and tried to make the letters light so they wouldn’t obscure the main parts of the graph. The x coordinates were just the center of the word and essentially the middle of the day. The first day starts at x=24 so 12 hours later or x=36 would be halfway through the day, approximately. I just had a list of the three-character day names and looped through them bumping the x location up by 24 hours for each day.
But the y coordinate was more complicated. I started out just choosing a fixed location for y like -5. For one database this worked fine. Then I tried another database, and it was way off. The reason is that Matplotlib scales the y coordinates based on the graphed data. If your database’s cpu is always around 30% then the range of visible y coordinates will be close to that. If your database’s cpu varies widely from 0% to 100% then Matplotlib will set the scale wide enough so the entire range 0 to 100 is visible. So, to put the text where I wanted it, just below the y axis line, I needed to make it a percentage of the visible y range below the lowest visible value. The get_ylim() method shows the calculated lower and upper bounds of the y axis which were calculated based on the y values of the graphed points. I manually messed with the value for the variable fraction until it looked right on the screen. Then I ran the script with a variety of databases to make sure it looked right on all of them.
# show graph
plt.show()
Lastly you just show the graph. Note that like the subplots() call this is not a method of an axes or figure object but just a matplotlib.pyplot call. Everything else in this example is a call to a method of the ax Axes type object.
Conclusion
This post shows how to graph Oracle database data using Python libraries cx_Oracle, NumPy, and Matplotlib. It first shows how to pull Oracle data into Python’s native data structures like lists and tuples. Then it shows how to convert the data into NumPy’s ndarrays and manipulate the data so that it can be graphed. Lastly it shows how to use Matplotlib Axes object methods to graph the data and add useful elements to the graph such as labels, vertical lines, and text.
This is a simple example, and all the software involved is free, open-source, widely used, easy to install, and well-documented. Give it a try!
I am not a very good blogger. Only four posts in 2024. I will need to pick it up because I just increased my spend on AWS for this blog. This site kept going down and I finally spent a few minutes looking at it and found that it was running out of memory. I was running on a minimal t2.micro EC2 which has 1 virtual CPU and 1 gigabyte of memory with no swap. So, rather than just add swap I bumped it up to a t3.small and paid for a 3-year reserved instance. It was about $220, nothing outrageous. Worth it to me. I still have two years left on the t2.micro reserved instance that I was using for the blog so I need to find a use for it, but I don’t regret upgrading. I spent a little money to make the site more capable so now I must write more posts!
I have three Machine Learning books to work through. After finishing my edX ML class with Python I picked up a book that covered the same topics and used the same Python libraries and I have been steadily working through it: Machine Learning with PyTorch and Scikit-Learn. I am on chapter 9 and want to get up to chapter 16 which covers Transformers. My edX class got up to the material in chapter 15 so the book would add to what was taught in the class. Earlier chapters also expand on what was taught in the class. The cool thing about the book is the included code. Lots of nice code examples to refer to later. Even the Matplotlib code for the graphs could be very helpful to me. I’ve gotten away from using Matplotlib after using it in my PythonDBAGraphs scripts.
My birthday is the day after Christmas, so I get all my presents for the year at the end of December. I got two ML books for Christmas/Birthday. Probably the first I will dive into after I finish the PyTorch/Scikit-Learn book is Natural Language Processing with Python. This is available for free on the NLTK web site. I have the original printed book. I think once I get through the Transformers chapter of the PyTorch book it makes sense to look at natural language processing since that is what ChatGPT and such is all about. I have played with some of this already, but I like the idea of working through these books.
The second book that I got in December as a present seems more technical and math related, although the author claims to have kept the math to a minimum. It is Pattern Recognition and Machine-Learning. This might be a slower read. It seems to be available for free as a PDF. ChatGPT recommended this and the NLTK book when I was chatting with it about my desire to learn more about Artificial Intelligence and Machine Learning.
I have all these conversations with ChatGPT about whether it makes sense for me as an Oracle database specialist to learn about machine learning. It assures me that I should, but it might be biased in favor of ML. Oracle 23ai does have AI in its name and does have some machine learning features. But it could just be a fad that blows over after the AI bubble bursts as many have before it. I can’t predict that. My current job title is “Technical Architect”. I work on a DBA team and I’m in the on-call rotation like everyone else, but my role includes learning about new technology. Plus, I think that I personally add value because of some of the computer science background I had in school and that I have been refreshing in recent years. Plus, I need to get some level of understanding of machine learning for my own understanding regardless of how much we do or don’t use it for my job. Just being a citizen of the world with a computer science orientation I feel is enough motivation to get up to speed on recent AI advancements. Am I misguided to think I should study machine learning?
Despite all this talk about AI, I am still interested in databases. I have this folder on my laptop called “Limits of SQL Optimization”. I had these grandiose ideas about writing interesting blog posts about what SQL could or couldn’t do without human intervention. Maybe SQL is a little like AI because the optimizer does what a human programmer would have to do without it. I’m interested in it all really. I like learning about how computer things work. I’ve spent my career so far working with SQL statements and trying to understand how the database system processes them. I thought about playing with MySQL’s source code. I downloaded it and compiled it but that’s about it. Plus, some day we will have Oracle 23ai and I’ll have to figure out how to support it in our environment, even if we do not use its AI features. Anyway, I’m sure I will have some non-AI database things to post about here.
To wrap up I think I may have some things to post on this blog in 2025, so it’s worth the extra expense to keep it running. Could be some more machine learning/artificial intelligence coming as I work through my books. I still have databases on the brain. Wish you all a great new year.
In my previous post I mentioned that I took a machine learning class based on Python and a library called PyTorch. Since the class ended, I have been working on a useful application of the PyTorch library and machine learning ideas to my work with Oracle databases. I do not have a fully baked script to share today but I wanted to show some things I am exploring about the relationship between the current date and time and database performance metrics such as host CPU utilization percentage. I have an example that you can download here: datetimeml2.zip
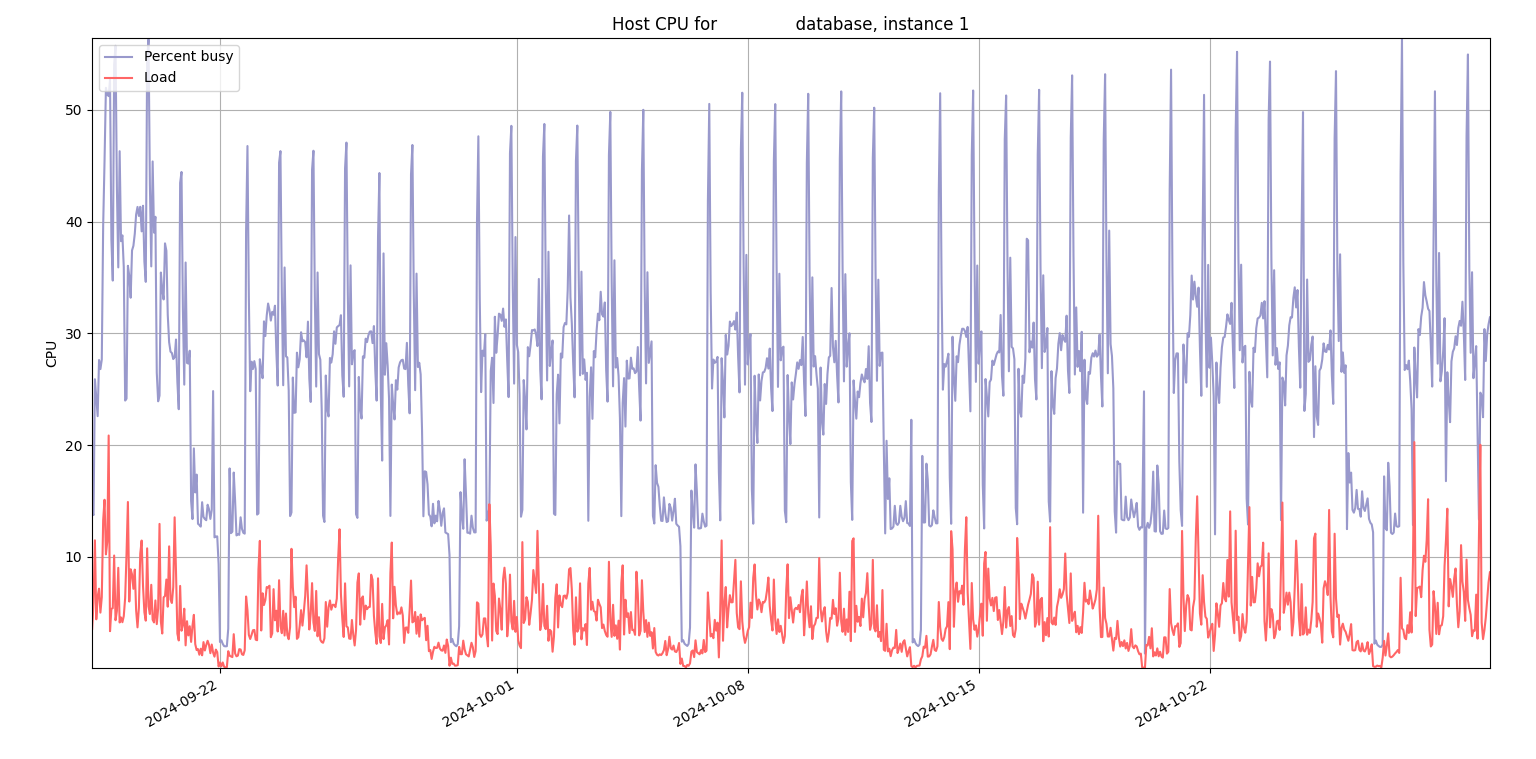
There is a relationship between the day of the week and the hour of the day and database performance metrics on many Oracle database systems. This is a graph from my hostcpu.py script that shows CPU utilization on a production Oracle database by date and hour of the day:
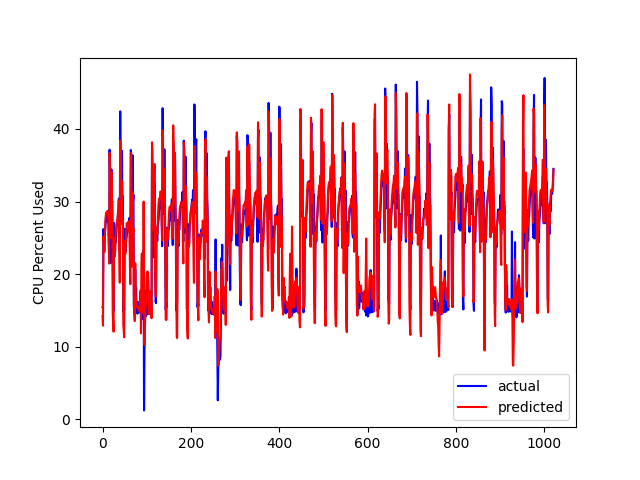
During the weekdays the CPU peaks at a certain hour and on the weekends, there are some valleys. So, I thought I would use PyTorch to model this relationship. Here is what the graph looks like of actual host CPU used versus predicted by PyTorch:
It’s the same source database but an earlier date. The prediction is close. I guess the big question after I got to this point was, so what? I’m not sure exactly what to do with it now that I have a model of the database CPU. I guess if the CPU is at 100% for an entire day instead of going up and down, I should throw an alert? What if CPU stays near 0% for a day during the week? It must be helpful to have a prediction of the host CPU but exactly how to alert on deviations from the predicted value is still a work in progress.
I thought it would be helpful to talk about the date and time inputs to this model. If you look at datetimeoscpu.sql in the zip it has this SQL for getting the date and time values:
I ended up ignoring year because it is not a cyclical value. The rest have a range like 1 to 7 for day of week or 1 to 31 for day of month. Having all eight of these is probably overkill. I could just focus on day of week and hour of day and forget the other six. We have 6 weeks of AWR history so I’m not sure why I care about things like month, quarter, day of year because I don’t have multiple years of history to find a pattern.
Each line represents an AWR snapshot. The first 8 are the cyclical date and time input values or X. The last value is the host CPU utilization percentage or Y. The point of the program is to create a model based on this data that will take in the 8 values and put out a predicted CPU percentage. This code was used to make the predictions for the graph at the end of the train.py script:
predictions = model(new_X)
When I first started working on this script it was not working well at all. I talked with ChatGPT about it and discovered that cyclical values like hour of day would work better with a PyTorch model if they were run through sine and cosine to transform them into the range -1 to 1. Otherwise PyTorch thinks that an hour like 23 is far apart from the hour 0 when really, they are adjacent. Evidently if you have both cosine and sine their different phases help the model use the cyclical date and time values. So, here is the code of the function which does sine and cosine:
def sinecosineone(dttmval,period):
"""
Use both sine and cosine for each of the periodic
date and time values like hour of day or
day of month
"""
# Convert dttmval to radians
radians = (2 * np.pi * dttmval) / period
# Apply sine and cosine transformations
sin_dttmval = np.sin(radians)
cos_dttmval = np.cos(radians)
return sin_dttmval, cos_dttmval
def sinecosineall(X):
"""
Column Number
day_of_week 7
day_of_month 31
day_of_year 366
hour_of_day 24
month 12
quarter 4
week_of_year 52
week_of_month 5
"""
...
The period is how many are in the range – 24 for hour of the day. Here is the hour 23 and hour 0 example:
Notice how the two values are close together for the two hours that are close in time. After running all my input data through these sine and cosine procedures they are all in the range -1.0 to 1.0 and these were fed into the model during training. Once I switched to this method of transforming the data the model suddenly became much better at predicting the CPU.
You can play with the scripts in the zip. I really hacked the Python script together based on code from ChatGPT, and I think one function from my class. It isn’t pretty. But you are welcome to it.
I’m starting to get excited about PyTorch. There are a bunch of things you must learn initially but the fundamental point seems simple. You start with a bunch of existing data and train a model that can be used as a function that maps the inputs to the outputs just as they were in the original data. This post was about an example of inputting cyclical date and time values like time of day or day of week and outputting performance metrics like CPU used percentage. I don’t have a perfect script that I have used to great results in production, but I am impressed by PyTorch’s ability to predict database server host CPU percent based on date and time values. More posts to come, but I thought I would get this out there even though it is imperfect. I hope that it is helpful.
In this post, I will describe the AI training resources that I am using in my quest to catch up with the current state of the art. My goal is to document the resources that I used for my own reference and to benefit others while explaining my reasoning along the way.
After studying AI back in the 1980s, I have not kept my AI skills up to date until recently when I started learning about newer things like ChatGPT. AI is in the news and every technical person should learn something about it for their own understanding and to help their career. Because I had a good overall understanding of the state of AI years ago, I think of it as “catching up” with the present-day standard. So, my approach makes sense for me given my history. But even for people who are not as old as I am or who don’t have the AI experience from their past the resources below could still be useful because of their overall quality.
Revisit AI Overview – 6.034
The first thing I did was watch the lecture videos for Patrick Winston‘s 2010 MIT 6.034 class. I had used Winston’s textbook in my college AI class in the 1980s. So, I thought that a class taught my Winston might follow a similar outline to what I once knew about AI and help jog my memory and catch me up with what has changed in the last 30+ years. Just watching the lecture videos and not doing the homework and reading limited how much I got from the class, but it was a great high-level overview of the different areas of AI. Also, since it was from 2010 it was good for me because it was closer to present day than my 1980s education, but 14 years away from the current ChatGPT hoopla. One very insightful part of the lecture videos is lectures 12A and 12B which are about neural nets and deep neural nets. Evidently in 2010 Professor Winston said that neural nets were not that promising or could not do that much. Fast forward 5 years and he revised that lecture with two more modern views on neural nets. Of course, ChatGPT is based on neural nets as are many other useful AI things today. After reviewing the 6.034 lecture videos I was on the lookout for a more in depth, hands on, class as the next step in my journey.
edX Class With Python – 6.86x
I had talked with ChatGPT about where to go next in my AI journey and it made various suggestions including books and web sites. I also searched around using Google. Then I noticed an edX class about AI called “Machine Learning with Python-From Linear Models to Deep Learning,” or “6.86x”. I was excited when I saw that edX had a useful Python-based AI class. I had a great time with the two earlier Python edX classes which I took in 2015. They were:
6.00.1x – Introduction to Computer Science and Programming Using Python
6.00.2x – Introduction to Computational Thinking and Data Science
This blog has several posts about how I used the material in those classes for my work. I have written many Python scripts to support my Oracle database work including my PythonDBAGraphs scripts for graphing Oracle performance metrics. I have gotten a lot of value from learning Python and libraries like Matplotlib in those free edX classes. So, when I saw this machine learning class with Python, I jumped at the chance to join it with the hope that it would have hands-on Python programming with libraries that I could use in my regular work just as the 2015 classes had.
Math Prerequisites
I almost didn’t take 6.86x because the prerequisites included vector calculus and linear algebra which are advanced areas of math. I may have taken these classes decades ago, but I haven’t used them since. I was afraid that I might be overwhelmed and not able to follow the class. But since I was auditing the class for free, I felt like I could “cheat” as much or as little as I wanted because the score in the class doesn’t count for anything. I used my favorite algebra system, Maxima, when it was too hard to do the math by hand. I had some very interesting conversations with ChatGPT about things I didn’t understand. My initial fears about the math were unfounded. The class helped you with the math as much as possible to make it easier to follow. And, at the end of the day since I wasn’t taking this class for any kind of credit, the points don’t matter. (like the Drew Carey improv show). What matters was that I got something out of it. I finished the class this weekend and although the math was hard at times I was able to get through it.
How to Finish Catching Up to 2024
It looks like 6.86x is 4-5 years old so it caught me up to 2019. I have been thinking about where to go from here to get all the way to present day. Working on this class I found two useful Python resources that I want to pursue more:
I walked away from both 6.034 and 6.86x realizing how important neural nets are to AI today and so I want to dig deeper into PyTorch which is a top Python library for neural nets originally developed by Facebook. With the importance of neural nets and the experience I got with PyTorch from the class it only makes sense to dig deeper into PyTorch as a tool that I can use in my database work. As I understand it Large Language Models such as those behind ChatGPT are built using tools like PyTorch. Plus, neural nets have many other applications outside of LLMs. I hope to find uses for PyTorch in my database work and post about them here.
Large Language Models with Hugging Face
Everyone is talking about ChatGPT and LLMs today. I ran across the Hugging Face site during my class. I can’t recall if the class used any of the models there or if I just ran across them as I was researching things. I would really like to download some of the models there and play with updating them and using them. I have played with LLM’s before but have not gotten very far. I tried out OpenAI’s API programming doing completions. I played with storing vectors in MongoDB. But I didn’t have the background that I have now from 6.86x to understand what I was working with. If I can find the time, I would like to both play with the models from Hugging Face and revisit my earlier experiments with OpenAI and MongoDB. Also, I think Oracle 23ai has vectors so I might try it out. But one thing at a time! First, I really want to dig into PyTorch and then mess with Hugging Face’s downloadable models.
Recap
I introduced several resources for learning about artificial intelligence. MIT’s OCW class from 2010, 6.034, has lecture videos from a well-known AI pioneer. 6.86x is a full-blown online machine learning class with Python that you can audit for free or take for credit. Python library PyTorch provides cutting edge neural net functionality. Hugging Face lets you download a wide variety of large language models. These are some great resources to propel me on my way to catching up with the present-day state of the art in AI, and I hope that they will help others in their own pursuits of AI understanding.
Bobby
P.S. Here are a couple of fun screenshots from the last project in my 6.86x class. Hopefully it won’t give too much away to future students.
This is a typical run using PyTorch to train a model for the last assignment.
This is the graphical output showing when the training converged on the desired output.
I was trying to tune a MySQL query this week. I ran the same query against Oracle with the same data and got a much faster runtime on Oracle. I couldn’t get MySQL to do a range scan on the column that Oracle was doing it on. So, I just started barely scratching the surface with a simple test of when MySQL will use an index versus a full table scan in a range query. In my test MySQL always uses an index except on extreme out of range conditions. This is funny because in my real problem query it was the opposite. But I might as well document what I found for what it’s worth. I haven’t blogged much lately.
This is on 8.0.26 as part of an AWS Aurora MySQL RDS instance with 2 cores and 16 gigabytes of RAM.
I created a simple test table and put 10485760 rows in it:
create table test
(a integer NOT NULL AUTO_INCREMENT,
b integer,
PRIMARY KEY (a));
The value of b is always 1 and a ranges from 1 to 10878873.
This query uses a range query using the index:
select
sum(b)
from
test
where
a > -2147483648;
This query uses a full table scan:
select
sum(b)
from
test
where
a > -2147483649;
The full scan is slightly faster.
Somehow when you are 2147483650 units away from the smallest value of a the MySQL optimizer suddenly thinks you need a full scan.
There are a million more tests I could do like things with a million variables, but I thought I might as well put this out there. I’m not really any the wiser but it is a type of test that might be worth mentioning.
-2147483648 is the smallest value for a 4 byte int type so that is probably why the behavior changes at -2147483649. Not sure what that information is worth!
P.P.S I think this explains why -2147483649 leads to the full scan in this case maybe:
“Beginning with MySQL 8.0.16, comparisons of columns of numeric types with constant values are checked and folded or removed for invalid or out-of-rage values”
Since -2147483648 is the smallest value for an int then with -2147483649 the optimizer removes the condition.
I wrote a script called archivelogspace.py to help size our Oracle archive log filesystems to support replication tools such as Fivetran, DMS, or GoldenGate which need a certain number of hours or days of archive log history at all times. In many cases we had backups that removed all the archive logs after they had been backed up once. So, that is essentially zero hours of history. If we only backed up once per day, it really peaked out at 24 hours of history, but the minimum was zero. Our replication products need 24 hours minimum in some cases. In other cases, we needed different numbers of hours. Also, the log backups and deletes run multiple times a day and on different schedules on some systems.
I based archivelogspace.py on a simplistic idea which I know is not perfect but so far it has been helpful. So, I thought I would share it here in case others can benefit. I would love any feedback, suggestions and criticism of the approach and implementation. The idea was to query V$ARCHIVED_LOG and see how full the filesystem would get if these same logs came in at the same times but with different retention times and different archive log filesystem sizes. I could try different settings and see the highest percentage that the filesystem hit.
I think this approach is imperfect because the past behavior recorded in V$ARCHIVED_LOG may not represent future behavior very well as things change. Also, the way I wrote it I assumed that the archive logs are laid down instantaneously. I.e. If the row in V$ARCHIVED_LOG has COMPLETION_TIME of 2/24/2024 16:11:15 then I assume that the filesystem gets (BLOCKS+1)*BLOCK_SIZE bytes fuller in that second. I also assume that the backups instantly remove all the logs which are beyond the retention.
I tested the script using the current settings for the archive log filesystem size and log backup run times and retention settings. I just compared the output percent full with reality. It was close but not exact. So, when I went to apply this for real, I padded the filesystem sizes so the expected percent full was less than 50%. So far so good in reality. I would like to build an emergency script that automatically clears out old logs if the filesystem gets full but so far, I have not. We do have alerting on archive log filesystem space getting too full.
If you run the script, you can see the arguments:
Arguments: oracle-username oracle-password tns-name configfile-name
Config file is text file with this format:
archivelog filesystem size in bytes
number of backups per day
one line per backup with 24-hour:minutes:seconds archivlog-retention-hours
for example:
8795958804480
6
02:15:00 168
06:15:00 168
10:45:00 168
14:15:00 168
18:15:00 168
22:15:00 168
The output is something like this:
2024-02-20 08:55:57 1.67%
2024-02-20 09:10:02 1.68%
2024-02-20 10:00:29 1.69%
2024-02-20 11:00:20 1.7%
2024-02-20 11:37:32 1.7%
2024-02-20 12:01:17 1.68%
2024-02-20 12:09:05 1.68%
2024-02-20 12:43:53 1.69%
2024-02-20 12:55:52 1.69%
Max percent used archivelog filesystem: 46.15%
Date and time of max percent: 2023-12-24 11:52:17
When your archive log filesystem is too small the Max percent is over 100%.
It’s not perfect or fancy but it is available if someone finds it useful.
Bobby
p.s. The script uses cx_Oracle so you will need to install that.
I keep running into situations on Oracle databases where I need to dump out the privileges an Oracle user has. I have been just manually putting together SQL statements like:
select * from dba_role_privs where grantee='MYUSER';
select * from dba_sys_privs where grantee='MYUSER';
select * from dba_tab_privs where grantee='MYUSER';
select * from dba_users where username='MYUSER';
This captures the three kinds of grants the user could have in the first three queries and the last query just shows if the user exists and things like whether it is locked. Really this simple set of queries is good enough in most cases.
But I had also wrote a script that would show all the system and object grants that were included in the roles. Because you can have roles granted to roles, you must loop through all the roles until you get down to the base system and object privileges. I rewrote this logic from scratch several times until I finally convinced myself to make a script and save it on my GitHub site. The current version of the script is here:
The interesting part of the script is where we keep looping through the roles in table my_role_privs deleting each role and then inserting the role’s system, object, and role privileges into the my_sys_privs, my_tab_privs, and my_role_privs tables. Eventually you run out of roles to delete and the loop finishes. I guess this works because you cannot have a circular role grant situation:
SQL> create role a;
Role created.
SQL> create role b;
Role created.
SQL> grant a to b;
Grant succeeded.
SQL> grant b to a;
grant b to a
*
ERROR at line 1:
ORA-01934: circular role grant detected
In the past I have put a loop counter in the code just in case there was something circular or a really long chain of roles, but this version does not have it.
To make the output useful I put it in three sections. The first section just has the direct grants and corresponds to the first three queries listed above.
Privileges granted directly to user MYUSER
Role privileges for user MYUSER
GRANTED_ROLE
--------------------
DBA
RESOURCE
System privileges for user MYUSER
PRIVILEGE
----------------------------------------
SELECT ANY TABLE
UNLIMITED TABLESPACE
Summarized table privileges for user MYUSER
OWNER PRIVILEGE COUNT(*)
-------------------- ---------------------------------------- ----------
SYS EXECUTE 1
Detailed table privileges for user MYUSER
PRIVILEGE OWNER TABLE_NAME
---------------------------------------- -------------------- -----------
EXECUTE SYS DBMS_RANDOM
I put counts of each type of object grants in case there was a bunch. I called them table privileges because view is named dba_tab_privs but I really should have called them object privileges because they can be grants on objects which are not tables.
The second section has the output of the loop showing all the system and object privileges implied by the role grants as well as those granted directly to the user:
Privileges granted through a role or directly to user MYUSER
System privileges for user MYUSER
PRIVILEGE
----------------------------------------
ADMINISTER ANY SQL TUNING SET
ADMINISTER DATABASE TRIGGER
ADMINISTER RESOURCE MANAGER
...
Summarized table privileges for user MYUSER
OWNER PRIVILEGE COUNT(*)
-------------------- ---------------------------------------- ----------
AUDSYS EXECUTE 1
GSMADMIN_INTERNAL EXECUTE 1
OUTLN SELECT 3
SYS DELETE 11
SYS EXECUTE 169
SYS FLASHBACK 14
SYS INSERT 12
SYS READ 15
SYS SELECT 4759
...
Detailed table privileges for user MYUSER
PRIVILEGE OWNER TABLE_NAME
---------------------------------------- -------------------- ------------------------
DELETE SYS AUX_STATS$
DELETE SYS DBA_REGISTRY_SQLPATCH
DELETE SYS EXPIMP_TTS_CT$
DELETE SYS INCEXP
DELETE SYS INCFIL
...
I use this a lot of times to see if a user has CREATE SESSION either directly or through a role so that I will know whether the user can login.
Lastly, I included a couple of details about the user at the end:
Account status, last password change for user ZBL6050
ACCOUNT_STATUS LAST_PASSWORD_CHNG
-------------------------------- -------------------
OPEN 2023-10-10 11:01:01
You need to give the user that runs userprivs.sql SELECT on sys.user$ to get the last password changed date and time. Otherwise, this query returns an error.
I mainly use this script to validate if a user has the correct permissions and if they can log in, so putting this information at the end in addition to the grant information above just fills in some details I would have to query anyway. I.e., Is the user locked? How long since they changed their password?
I thought about bringing down some statement about CREATE SESSION here. As it is written now, I have to visually scan the system privileges for CREATE SESSION to get the full picture on the user’s ability to login. It might be nice to add a column “Has CREATE SESSION” to this screen.
There are probably fancier scripts and tools to do all this, but this is what I have been using and the reasoning behind it. Maybe it will be useful to others and a reminder to myself to document it here.
I was in a short programming contest at work for three days last week. My team got second place! We used a LangChainvector store in a MongoDB Atlas cluster so I thought I would at least document the links we referred to and videos I watched for others who are interested.
Then I watched this video about the new MongoDB Atlas Vector Search feature:
This video is totally worth watching. I got a ton out of it. After watching the video I redid the VectorStore example but with MongoDB Atlas as the database:
I got in a discussion with ChatGPT about why they call them “vectors” instead of “points”. A vector is just an array or list of floating point numbers. In math this could be a point in some multi-dimensional space. ChatGPT didn’t seem to realize that software does use the vectors as vectors in a math sense sometimes. The MongoDB Atlas index we used cosine similarity which must be related to the vectors with some common starting point like all zeroes pointing towards the point represented by the list of numbers in the “vector”.
When I created the search index in MongoDB Atlas I forgot to name it and it did not work since the code has the index name. For the sample the index name has to be langchain_demo. By default index name is “default”.
LangChain itself was new to me. I watched the first video all the way through but there is a lot I did not use or need. I had played with OpenAI in Python already following the Python version of this quick start:
I edited the example script and played with different things. But I had never tried LangChain which sits on top of OpenAI and simplifies and expands it.
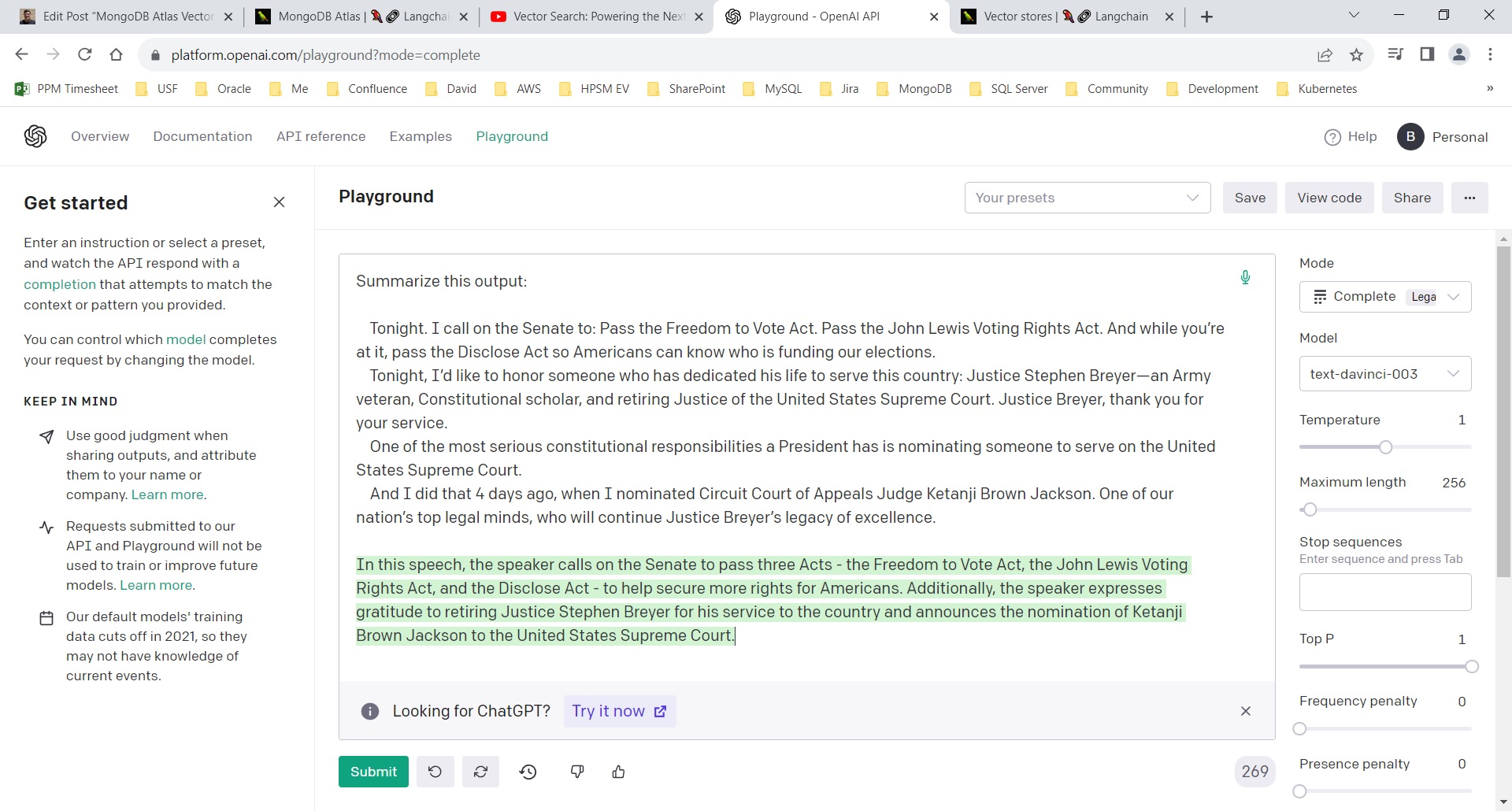
The project we worked on for the contest implemented the architecture documented at 28:57 in the MongoDB video above. If you look at the MongoDB Atlas vector store example this “information flow” would take the output from docsearch.similarity_search(query) and send it through OpenAI to summarize. If you take the piece of the President’s speech that is returned by the similarity search and past it into OpenAI’s playground the result looks like this:
So, our programming project involved pulling in documents that were split up into pieces and then retrieve a piece based on a similarity query using the vector store and then ran that piece through OpenAI to generate a readable English summary.
So, I am an Oracle database administrator. I have been for about 30 years starting with Oracle 7. But for the past few years we have been supporting MySQL in Amazon Web Services’ RDS version. Unfortunately, we have been forced to embrace the Aurora version of MySQL also which is proprietary to Amazon and does not have the full source code. But we still have several vanilla MySQL RDS instances that we support.
Working with Oracle for so many years I have tried to learn about its internals – how does it really work? This is difficult because I do not have access to Oracle’s source code and even if I did, I probably do not have enough years remaining in my life to ever fully understand it. Still, the idea of working with the MySQL community edition version that we have the full source code to has always intrigued me. This is similar to my fascination with the antique computer game Nethack that I play in a character-based mode exploring a dungeon and fighting monsters. It is a good game, but more importantly, I have the full source code.
Who knows? Maybe when we are working with MySQL we will run across a bug, and I will be able to dig into the part of the code that has the bug and it will help me figure out how to solve the problem. With Oracle it is always a guess what is going on. It can be an educated guess based on what Oracle reveals through various traces and logs. But maybe even though I do not have the time and motivation to be a hardcore MySQL internals developer there could be a situation where having the source code will help.
So, that leads me to want to download the exact version of the MySQL source code that we are using on AWS RDS and compile it, link it, install it on a test VM on the chance that someday I will need a working test MySQL database of the same version as one that is having a problem in production.
Things have changed since my 5/22/2019 post about setting up this kind of environment. At that time, I was working with an Oracle Linux 7 VM running on my work laptop with all its firewalls and Zscaler and all between my VM and the internet. Today I am using Oracle Linux 8 running on a VM on a personal laptop which is on my home network so there is nothing in the way of my downloading things from the internet like Linux rpm packages. One of the side effects of COVID-19 is that I am working from home full time. Also, not due to COVID, my middle daughter moved out leaving her bedroom open to be converted to an office. So, I have two “desks” setup with two laptops and big monitors on both. My home laptop sits to my left and I can run VirtualBox VMs on it without being on our corporate network. This is great for testing where I just need to setup a technology and I do not need or even want access to something on our corporate network.
So, with all this prelude let me tell you some of the things I had to do to get the MySQL 5.7.38 source code compiled on my Oracle Linux 8 VM.
I cloned a OEL 8 VM that I already had and then updated the packages. I think I used yum instead of dnf which was dumb, but it worked.
Once I had an up-to-date OEL 8 environment I had to get the source tree for MySQL with the right commit point for 5.7.38. I was following this document:
I installed Boost and Cmake like what I did in the earlier post. I got the rest of the development tools like gcc, make, bison in place using this dnf command:
dnf groupinstall "Development Tools"
Then I had to get the cmake command to work:
cmake . -DWITH_BOOST=/home/bobby/boost_1_59_0
I had to install several packages before I could get this to run without errors. I had to enable the “CodeReady Builder” repository in the file oracle-linux-ol8.repo:
Eventually I realized that after messing with adding the new repository and packages I needed to go back and clean everything up and run cmake again:
make clean
rm CMakeCache.txt
cmake . -DWITH_BOOST=/home/bobby/boost_1_59_0
make
su -
make install
Other than that, it is just the normal steps to create the database and run it, which I think is documented in my earlier post and in the MySQL docs.
I thought it couldn’t hurt to document the things I had to do if nothing else for myself. I use this blog as a reference for myself, so it is not just something for other people to read. Anyway, I’m glad I could get this down and maybe someone else will benefit.