I just finished another production tuning exercise that is like two recent posts:
Two New ASH FORCE_MATCHING_SIGNATURE scripts
Tuning Example With Outline Hints and SQL Profile
The biggest new thing was that I ran the ashtopelapsed.sql script that I mentioned in the first post above but it missed the top SQL statement for the job I was trying to tune. I am struggling to get the logic right. I am trying to write an ASH-based top SQL report for a given time range. It is like an AWR report where you see the top elapsed time SQL statement for the given time frame. But I am grouping by FORCE_MATCHING_SIGNATURE and not SQL_ID because I want to see the top SQL that all have the same signature but different SQL_IDs. In this case there was a PeopleSoft update and select statement that did not use bind variables, so each execution had its own SQL_ID. Here is the select:
SELECT
DISTINCT TO_CHAR(A.ACCOUNTING_DT,'YYYY-MM-DD')
FROM PS_HR_ACCTG_LINE A
WHERE
A.APPL_JRNL_ID = 'ABCDE' AND
A.BUSINESS_UNIT_GL = 'FG' AND
(A.LEDGER_GROUP = ' ' OR A.LEDGER_GROUP = 'HIJK') AND
A.GL_DISTRIB_STATUS = 'N' AND
A.ACCOUNTING_DT >= TO_DATE('2006-09-03','YYYY-MM-DD') AND
A.ACCOUNTING_DT <= TO_DATE('2021-09-04','YYYY-MM-DD');I guess this runs for different values of BUSINESS_UNIT_GL, ACCOUNTING_DT, etc.
I am trying to get ashtopelapsed.sql to show the top SQL by force matching signature:
create table topsigs as
select
FORCE_MATCHING_SIGNATURE,
count(*) active
from DBA_HIST_ACTIVE_SESS_HISTORY a
where
sample_time
between
to_date('13-SEP-2021 01:00:19','DD-MON-YYYY HH24:MI:SS')
and
to_date('13-SEP-2021 06:52:25','DD-MON-YYYY HH24:MI:SS')
group by
FORCE_MATCHING_SIGNATURE;In this case during the time frame of the problem job, from about 1 to 7 am yesterday.
But then I want to find at least one SQL_ID for the given value of FORCE_MATCHING_SIGNATURE so I can then get its text as an example of a real SQL statement that has the signature:
create table sigtoid as
select
t.FORCE_MATCHING_SIGNATURE,
min(a.sql_id) a_sql_id
from
topsigs t,
DBA_HIST_ACTIVE_SESS_HISTORY a,
DBA_HIST_SQLTEXT s
where
t.FORCE_MATCHING_SIGNATURE = a.FORCE_MATCHING_SIGNATURE and
a.sql_id = s.sql_id
group by t.FORCE_MATCHING_SIGNATURE;
There has to be a row in DBA_HIST_SQLTEXT for the signature or else I will not have an example SQL statement and the signature will get dropped from the report. I may need to put some sort of outer join somewhere so I can see the FORCE_MATCHING_SIGNATURE values that do not have an example SQL_ID in DBA_HIST_SQLTEXT. But fortunately, with the last revision (commit) to ashtopelapsed.sql I was able to see the text of an example SQL statement for each of the top signatures during the time when the problem job ran.
The other funny thing is that I forgot I had ashfmscount.sql so I ended up rewriting it. I need to read my own blog posts. 🙂 Hopefully this more detailed post will serve as a model for future performance tuning efforts and so I will not forget the scripts that I used this time.
As for hacking a SQL Profile together, the subject of the second post above, I edited one in vi as described in the post and the other I just extracted using coe_xfr_sql_profile.sql. I also edited both SQL Profiles to use FORCE = TRUE to make the SQL profile apply to all SQL statements with the same signature. I described FORCE = TRUE in earlier posts:
force_match => TRUE option of DBMS_SQLTUNE.IMPORT_SQL_PROFILE
Example of coe_xfr_sql_profile force_match TRUE
I think there is some overlap in all these posts, but I wanted to document today’s tuning exercise. The biggest new thing is the improvement of ashtopelapsed.sql.
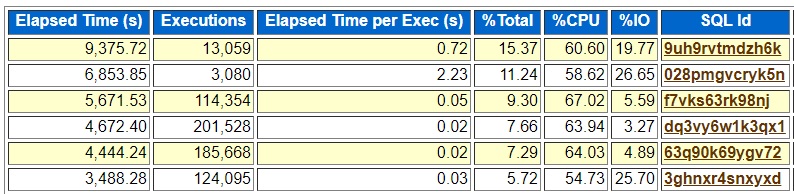
Couple of images of the AWR and ASH top SQL for the time of this long running job:
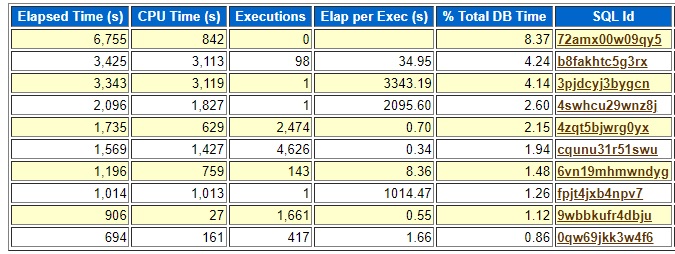
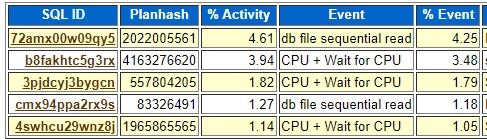
Neither of these captured the top SQL by signature so that is why ashtopelapsed.sql was helpful. There may be some Oracle supplied way to do the same thing that I do not know about but the standard awrrpt.sql and ashrpt.sql do not handle this situation well. I could not find any useful information about my long running job in the top SQL portions of the AWR and ASH reports.
Here is the top output from ashtopelapsed.sql:
ACTIVE FORCE_MATCHING_SIGNATURE EXAMPLE_SQL_I SQL_TEXT
---------- ------------------------ ------------- --------------------------
10389 0 02101wfuxvwtd INSERT INTO PS_AERUNCONTRO
1394 2407690495325880429 003t0wk45taqs UPDATE PS_HR_ACCTG_LINE SE
858 9373188292577351646 04hvza4k3u72x INSERT INTO PS_PROJ_RES_TM
ID, VOUCHER_ID, VOUCHER_LI
D_DETAIL, CST_DISTRIB_STAT
_TYPE, JL.RESOURCE_TYPE, J
JRNL_HEADER JH , PS_JRNL_L
718 810675553005238195 b8fakhtc5g3rx select * from (select a.os
646 12856152818202055532 00mmbs0c6bh1a SELECT DISTINCT TO_CHAR(A.
I created FORCE=TRUE SQL Profiles for FORCE_MATCHING_SIGNATURE values 2407690495325880429 and 12856152818202055532. Here was the output from ashfmscount.sql:
FORCE_MATCHING_SIGNATURE ACTIVE
------------------------ ----------
2407690495325880429 1394
12856152818202055532 646
12319028094632613940 43
12084330158653099691 2
10829167302201730459 2
4612906341224490548 1Almost all the 6-hour runtime was taken up by 2407690495325880429 and 12856152818202055532. The units are in 10 seconds so in hours it is:
((1394 + 646)*10)/3600.0 = 5.666666666666667
Almost all the job run time was spent on SQL statements that match these two signatures.
These two had full scans and needed index skip scans.
Bad plan:
Plan hash value: 3305693634
-----------------------------------------------
| Id | Operation | Name |
-----------------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | PS_HR_ACCTG_LINE |
| 2 | TABLE ACCESS FULL| PS_HR_ACCTG_LINE |
-----------------------------------------------
Good plan:
Plan hash value: 1538925713
---------------------------------------------------------
| Id | Operation | Name |
---------------------------------------------------------
| 0 | UPDATE STATEMENT | |
| 1 | UPDATE | PS_HR_ACCTG_LINE |
|* 2 | TABLE ACCESS BY INDEX ROWID| PS_HR_ACCTG_LINE |
|* 3 | INDEX SKIP SCAN | PSAHR_ACCTG_LINE |
---------------------------------------------------------
Not to beat a dead horse, but my main point is that I updated ashtopelapsed.sql to be useful in this situation. It gave me information that the AWR and ASH reports did not.
Here are the scripts that I used for this tuning example:
ashdump.sql – dump out a single 10 second point in time to find the session that is running the batch job
I also had to run this script which is not in my git repository (it is based on ashcount.sql which is my generic script for grouping by certain ash columns).
select
2 SESSION_ID,count(*) active
3 from DBA_HIST_ACTIVE_SESS_HISTORY a
4 where
5 sample_time
6 between
7 to_date('13-SEP-2021 01:00:19','DD-MON-YYYY HH24:MI:SS')
8 and
9 to_date('13-SEP-2021 06:52:25','DD-MON-YYYY HH24:MI:SS')
10 and program like 'PSAESRV%'
11 group by SESSION_ID
12 order by active desc;
SESSION_ID ACTIVE
---------- ----------
1039 2088
1005 957
858 804
1006 195
993 150
942 143
1060 114
940 109
927 69
1026 1I was trying to figure out which PSAESRV session was the one that ran all 6 hours. Session 1039 was the one, so I used it in ashfmscount.sql.
ashfmscount.sql – find the top signatures for the session that is the batch job
ashtopelapsed.sql – get the text of the top SQL statements grouped by signature in the time frame that the job ran
plan.sql – get a plan and output an outline hint to match it
test2.sql – test query with and without outline hint. also get plan hash value in memory so it can be extracted by sqlt.
optimizerstatistics – get index columns and column statistics
fmsstat2.sql – show execution history of 2407690495325880429 from AWR – here is before the profile:
FORCE_MATCHING_SIGNATURE SQL_ID PLAN_HASH_VALUE END_INTERVAL_TIME
------------------------ ------------- --------------- -------------------------
2407690495325880429 03jh5xnnsts7q 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 17wshhdq89azx 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 1k4a28bdg7r8h 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 3zhumhfujfwj5 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 59xs2q8215bby 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 666s10cy2k3fh 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 6bdybc28zn3fg 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 7050x70hjg5mj 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 7wvsquchacp2p 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 8yjhydta27wsn 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 ahj6g61c8hzcq 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 ba76xa0dpua3n 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 bfzkxy486cfu5 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 cg65kxmcytw00 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 d63wz9wyhp10y 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 dk7annutx6n4z 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 dpw0m2t5dmcs8 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 fx4q3cpn84zbf 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 gbc4ksykvucqk 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 gn81xu18vsctn 3305693634 06-AUG-21 02.00.46.749 AM
2407690495325880429 gxvwq870b82tg 3305693634 06-AUG-21 02.00.46.749 AM
vsqlarea.sql – show current execution details such as plan for 2407690495325880429 after the profile
LAST_ACTIVE FORCE_MATCHING_SIGNATURE SQL_ID PLAN_HASH_VALUE
------------------- ------------------------ ------------- ---------------
2021-09-14 17:54:36 2407690495325880429 5vczbrua1hnyk 1538925713
2021-09-14 17:54:36 2407690495325880429 gb7awt1g0spj3 1538925713
2021-09-14 17:54:34 2407690495325880429 54tz4ks94ard2 1538925713
2021-09-14 17:49:13 2407690495325880429 g9r370krad681 1538925713
2021-09-14 17:49:12 2407690495325880429 g4mqhstqmb616 1538925713
2021-09-14 17:43:19 2407690495325880429 apfc4uuksxzt2 1538925713
2021-09-14 17:43:18 2407690495325880429 g1k89u3xqb0nt 1538925713
2021-09-14 17:43:17 2407690495325880429 1rshyrb28xppz 1538925713
2021-09-14 17:36:52 2407690495325880429 934a88k6ct5ct 1538925713
The job ran last night in about 36 minutes instead of almost 6 hours, so it was a big improvement.
I was not able to improve the performance of this long running job using AWR or ASH reports but once I fixed an issue with my ashtopelapsed.sql script and used it along with my other ASH and non-ASH scripts I was able to resolve the performance issue. The job had many update and select statements that were too short to show up on the AWR and ASH reports but when summarized by their force matching signatures they showed up at the top of my ashtopelapsed.sql and ashfmscount.sql scripts’ outputs. Going forward I hope to use the collection of scripts described in this post when faced with tuning situations where an AWR report does not point to a top SQL statement. I may start using these on a regular basis even in cases where the AWR report does provide helpful information just to have another source of information.
Bobby