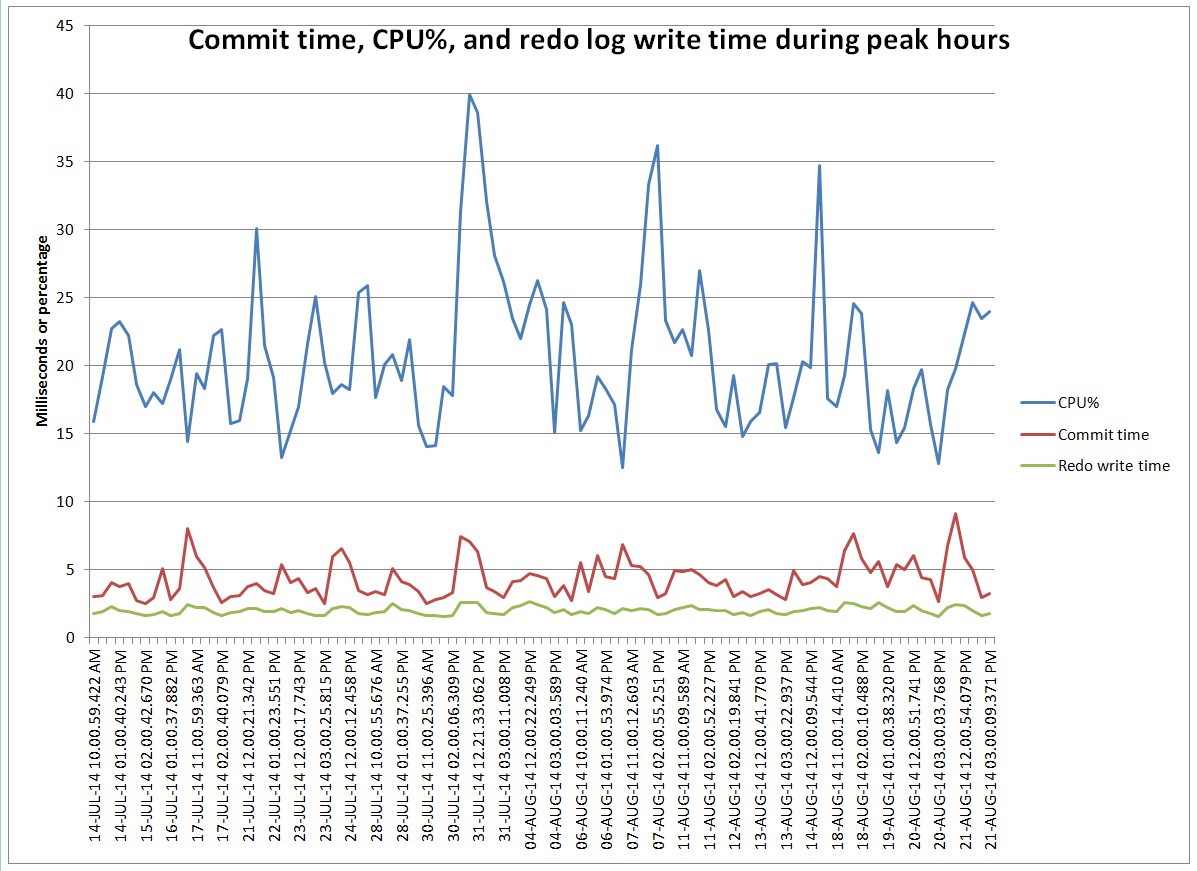
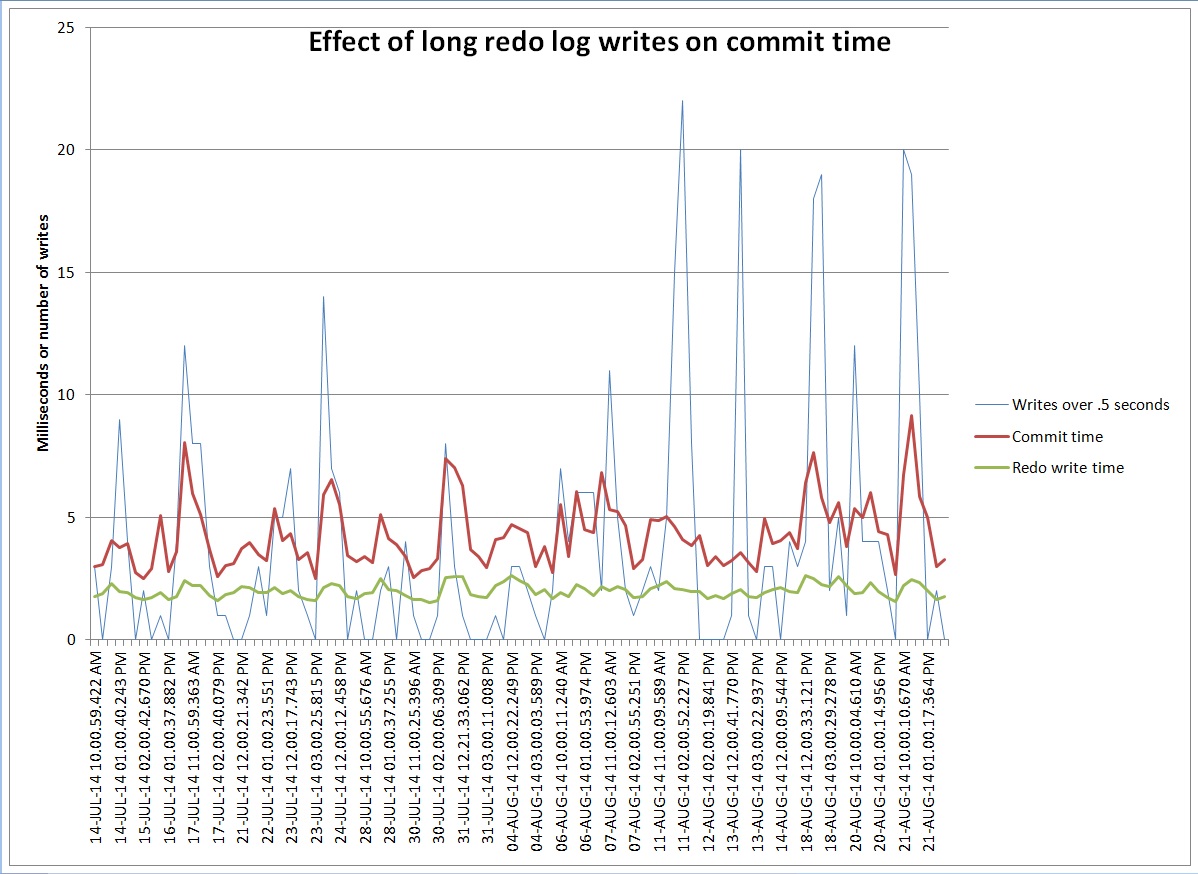
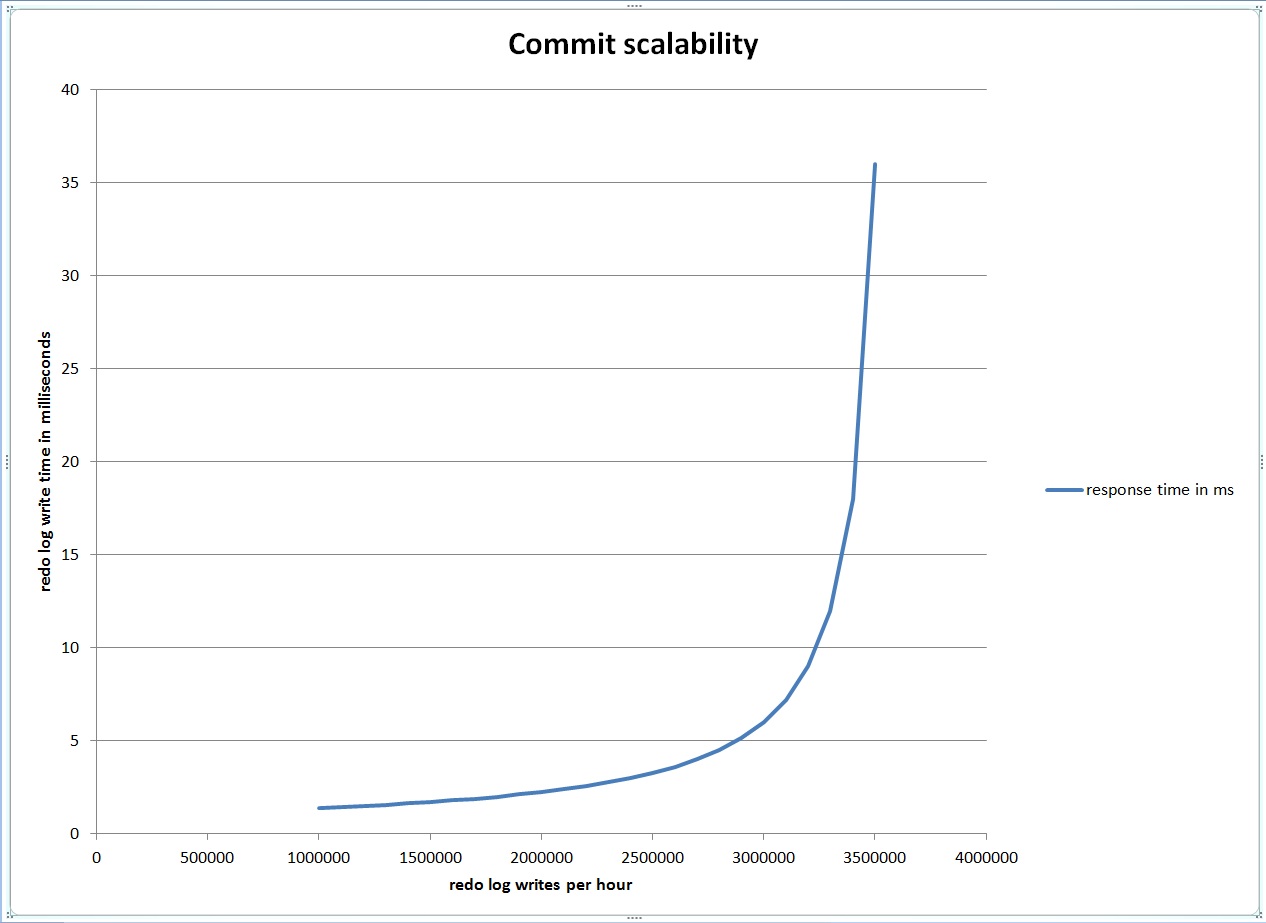
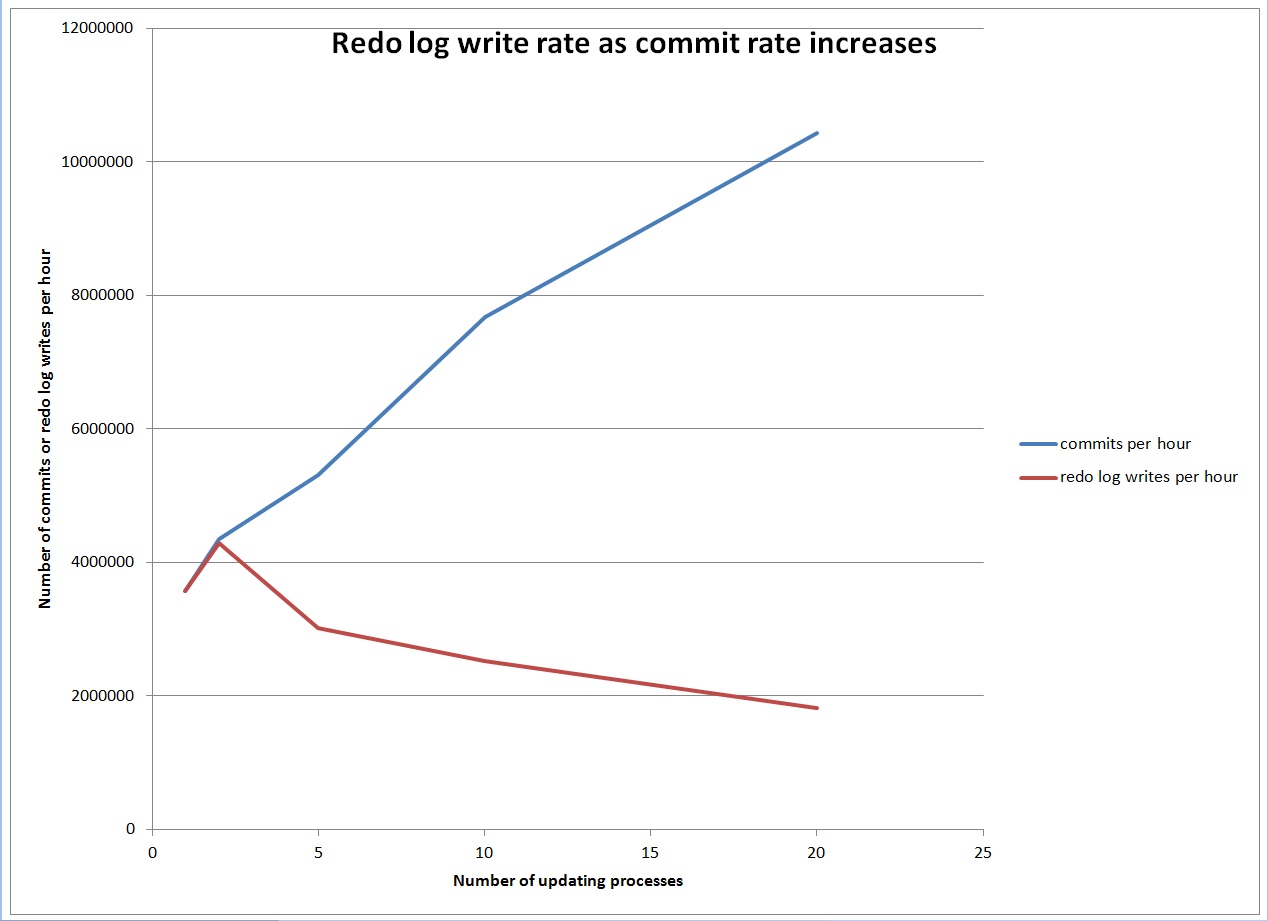
On Monday we had some performance problems on a system that includes a database which uses shared servers. The top wait was “virtual circuit wait”. Here are the top 5 events for a 52 minute time frame:
Top 5 Timed Foreground Events
| Event | Waits | Time(s) | Avg wait (ms) | % DB time | Wait Class |
|---|---|---|---|---|---|
| virtual circuit wait | 1,388,199 | 17,917 | 13 | 50.98 | Network |
| db file sequential read | 1,186,933 | 9,252 | 8 | 26.33 | User I/O |
| log file sync | 1,185,620 | 6,429 | 5 | 18.29 | Commit |
| DB CPU | 5,964 | 16.97 | |||
| enq: TX – row lock contention | 391 | 586 | 1499 | 1.67 | Application |
From other monitoring tools there was no sign of poor performance from the database end but virtual circuit wait is not normally the top wait during peak times. Overall for the time period of this AWR report the shared servers didn’t seem busy:
Shared Servers Utilization
| Total Server Time (s) | %Busy | %Idle | Incoming Net % | Outgoing Net % |
|---|---|---|---|---|
| 111,963 | 38.49 | 61.51 | 15.99 | 0.01 |
We have seen virtual circuit waits ever since we upgraded to 11g on this system so I wanted to learn more about what causes it. These two Oracle support documents were the most helpful:
Troubleshooting: Virtual Circuit Waits (Doc ID 1415999.1)
Bug 5689608: INACTIVE SESSION IS NOT RELEASING SHARED SERVER PROCESS (closed as not bug)
Evidently when you return a cursor from a package and the cursor includes a sort step a shared server will be hung up in a virtual circuit wait state from the time the cursor is first fetched until the application closes the cursor. Our application uses cursors in this way so it stands to reason that our virtual circuit wait times we saw in our AWR report represent the time it took for our web servers to fetch from the cursors and close them, at least for the cursors that included sort steps. So, if our web servers slow down due to some other issue they could potentially take longer to fetch from and close the affected cursors and this could result in higher virtual circuit wait times.
Here is a zip of a test script I ran and its output: zip
I took the test case documented in bug 5689608 and added queries to v$session_wait to show the current session’s virtual circuit waits.
Here are the first steps of the test case:
CREATE TABLE TEST AS SELECT * FROM DBA_OBJECTS; create or replace package cursor_package as cursor mycursor is select * from test order by object_name; end; / begin open cursor_package.mycursor; end; / create or replace procedure test_case is l_row TEST%rowtype; begin if cursor_package.mycursor%isopen then fetch cursor_package.mycursor into l_row; end if; end; /
These steps do the following:
- Create a test table
- Create a package with a cursor that includes an order by to force a sort
- Open the cursor
- Create a procedure to fetch the first row from the cursor
At this point I queried v$session_wait and found no waits:
SQL> select * from v$session_event
2 where sid=
3 (SELECT sid from v$session where audsid=USERENV('SESSIONID'))
and
4 event='virtual circuit wait';
no rows selected
The next step of the test case fetched the first row and then I queried and found the first wait:
SQL> exec test_case;
SQL> select * from v$session_event
2 where sid=
3 (SELECT sid from v$session where audsid=USERENV('SESSIONID'))
and
4 event='virtual circuit wait';
SID EVENT TIME_WAITED
---------- --------------------------------------------------------
783 virtual circuit wait 0
Note that time_waited is 0 which means the time was less than one hundredth of a second. Next I made my sqlplus client sleep for five seconds using a host command and looked at the wait again:
SQL> host sleep 5
SQL> select * from v$session_event
2 where sid=
3 (SELECT sid from v$session where audsid=USERENV('SESSIONID'))
and
4 event='virtual circuit wait';
SID EVENT TIME_WAITED
---------- --------------------------------------------------------
783 virtual circuit wait 507
Total time is now 507 centiseconds = 5 seconds, same as the sleep time. So, the time for the virtual circuit wait includes the time after the client does the first fetch, even if the client is idle. Next I closed the cursor and slept another 5 seconds:
SQL> begin
2 close cursor_package.mycursor;
3 end;
4 /
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.01
SQL>
SQL> host sleep 5
SQL>
SQL> select * from v$session_event
2 where sid=
3 (SELECT sid from v$session where audsid=USERENV('SESSIONID'))
and
4 event='virtual circuit wait';
SID EVENT TIME_WAITED
---------- --------------------------------------------------------
783 virtual circuit wait 509
The time waited is still just about 5 seconds so the clock stops on the virtual circuit wait after the sqlplus script closes the cursor. If the session was still waiting on virtual circuit wait after the close of the cursor the time would have been 10 seconds.
This was all new to me. Even though we have plenty of shared servers to handle the active sessions we still see virtual circuit waits. These waits correspond to time on the clients fetching from and closing cursors from called packages. As a result, these wait times represent time outside of the database and not time spent within the database. These waits tie up shared servers but as long as they are short enough and you have shared servers free they don’t represent a problem.
– Bobby
p.s. This is on hp-ux 11.31 ia64 Oracle 11.2.0.3