
I am learning about how well commits scale on Oracle 11.2 and so far they seem to scale surprisingly well.
I’ve looked at two waits – log file parallel write and log file sync. Based on documents I’ve read on Oracle’s support site log file parallel write represents the time it takes to do one write to the redo logs. For mirrored redo logs the log file parallel write time includes the time to write to both of the copies. Log file sync represents the time it takes for a session to complete a commit and should include all the time measured for the write to the redo logs and added CPU time to process the commit. So, the log file sync time should equal or exceed the log file parallel write time.
Looking at AWR data I found that at peak times one of our databases had 1 millisecond log file parallel write waits and about 1.2 million waits per hour. Since there are 3.6 million milliseconds in an hour it seemed to me that during this peak hour the redo logs were about 33% utilized because writes to the redo logs were occurring during 1.2 million of the available 3.6 million milliseconds. I decided to look at a simple queuing theory model that I had read about in Craig Shallahamer’s Forecasting Oracle Performance book to get a basic idea of how queuing might impact redo log write time as the utilization of the redo log grew closer to 100%.
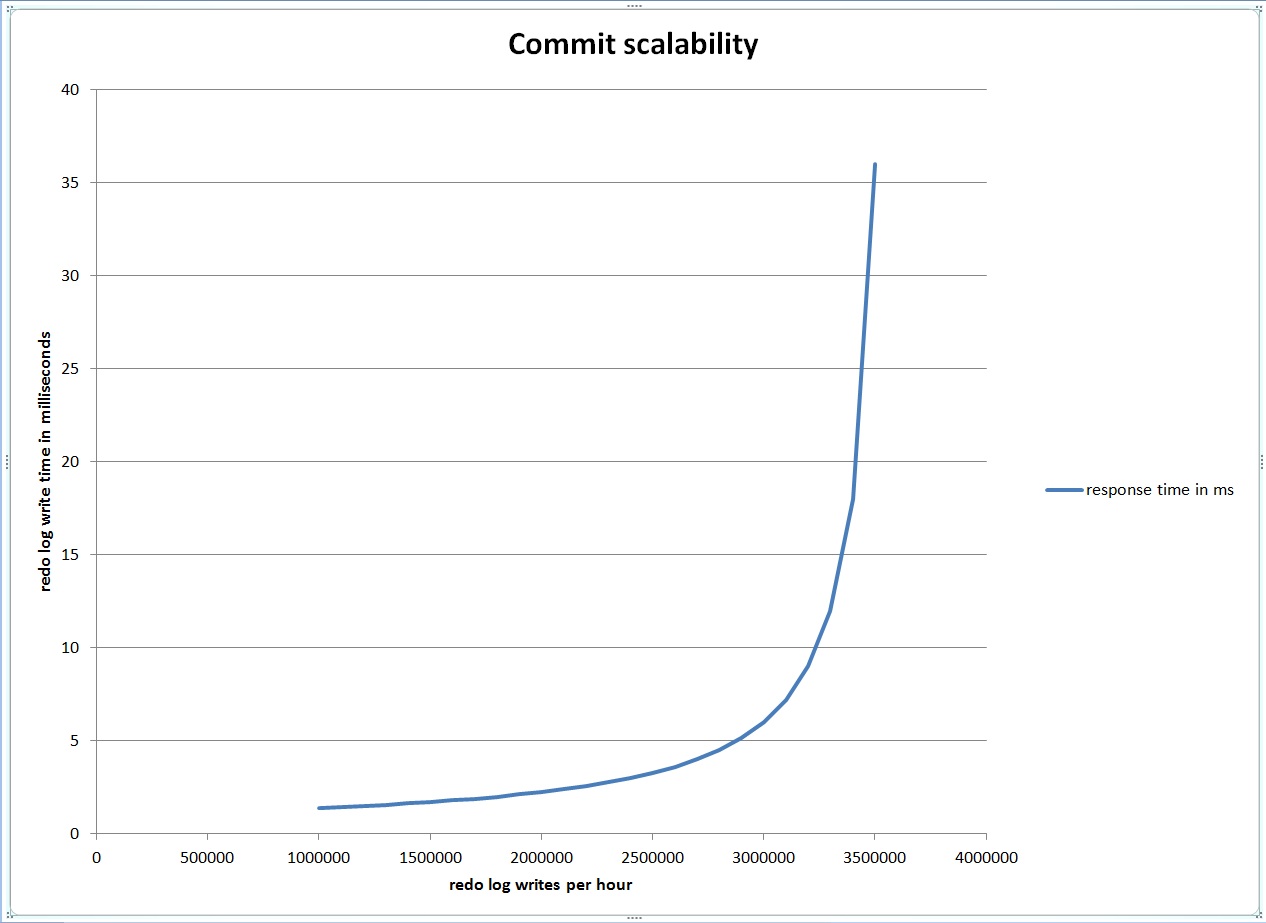
This model predicts that the redo log write time will go through the roof as the number of writes per hour approaches 3.6 million, assuming a constant 1 millisecond write time.
To attempt to confirm the predictions made by this graph I decided to build some scripts that will run a bunch of commits on a test database and attempt to max out the writes to the redo log so I could graph the results and compare it to the theoretical model. In the test I had twenty tables named TEST1, TEST2,…, TEST20. These tables have one row and one column. I ran a test of 1, 2, 5, 10, and 20 updating processes that I designed to generate a bunch of commits quickly. Each process ran 100,000 updates and commits like these:
update test1 set a=a+1;
commit;
update test1 set a=a+1;
commit;
update test1 set a=a+1;
commit;
…
Each process had its own table – i.e. process 15 acted on table TEST15.
My hope was that as I ran tests with increasing numbers of processes running in parallel eventually I would max out the writes to the redo log and see increasing log file parallel write wait times. But, surprisingly, as the commit rate increased the redo log write rate actually went down.
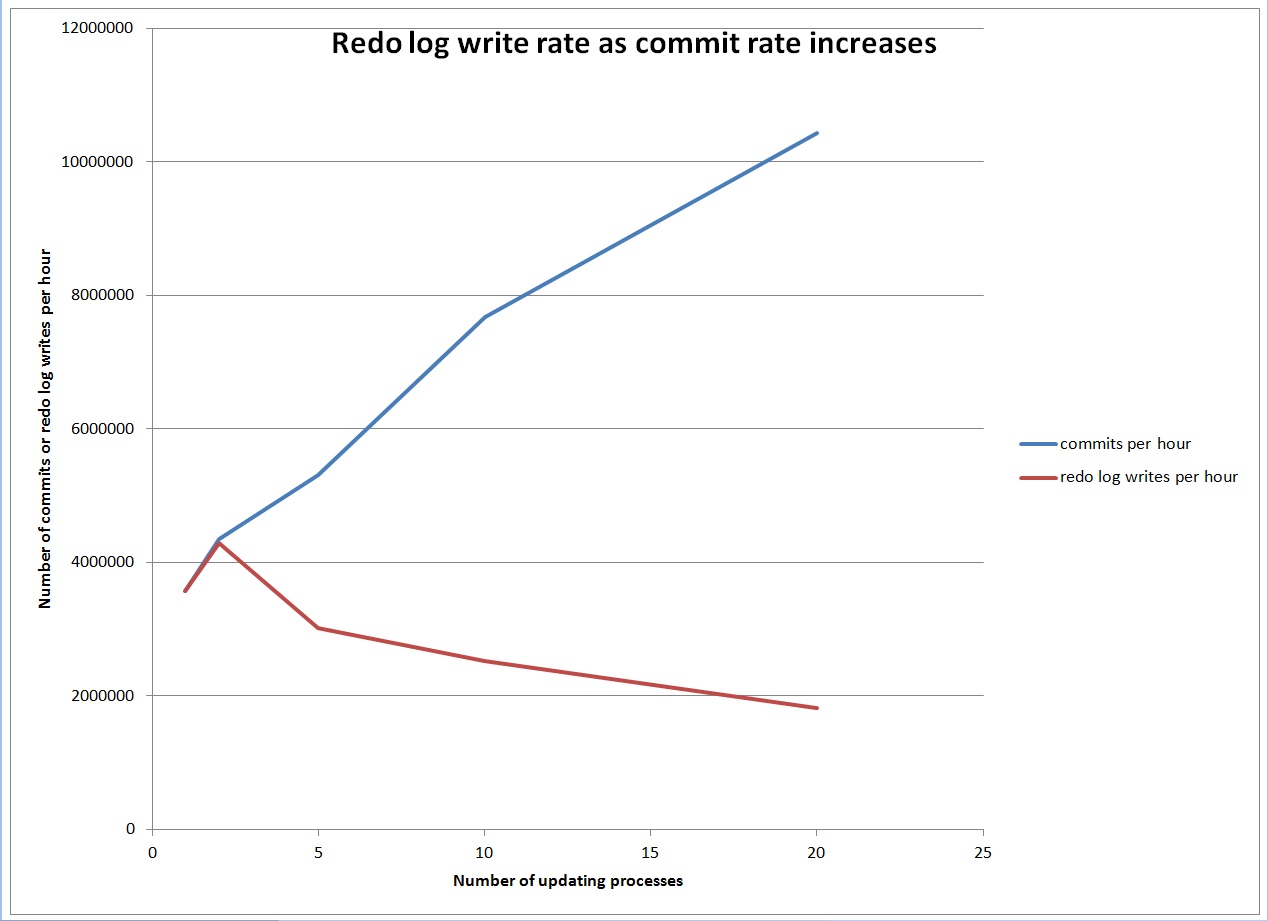
This is just one test, but it makes me wonder if I can max out the writes to the redo log. I believe that as the commit rate increases the database batches the commits together in some efficient way which makes commits more scalable than I realized.
I think that an Oracle database must have some limit to commit scalability that relates more to the CPU used to process the commits instead of the writes to the redo logs. In these same tests the log file sync or commit time did increase slowly as the number of commits ramped up.
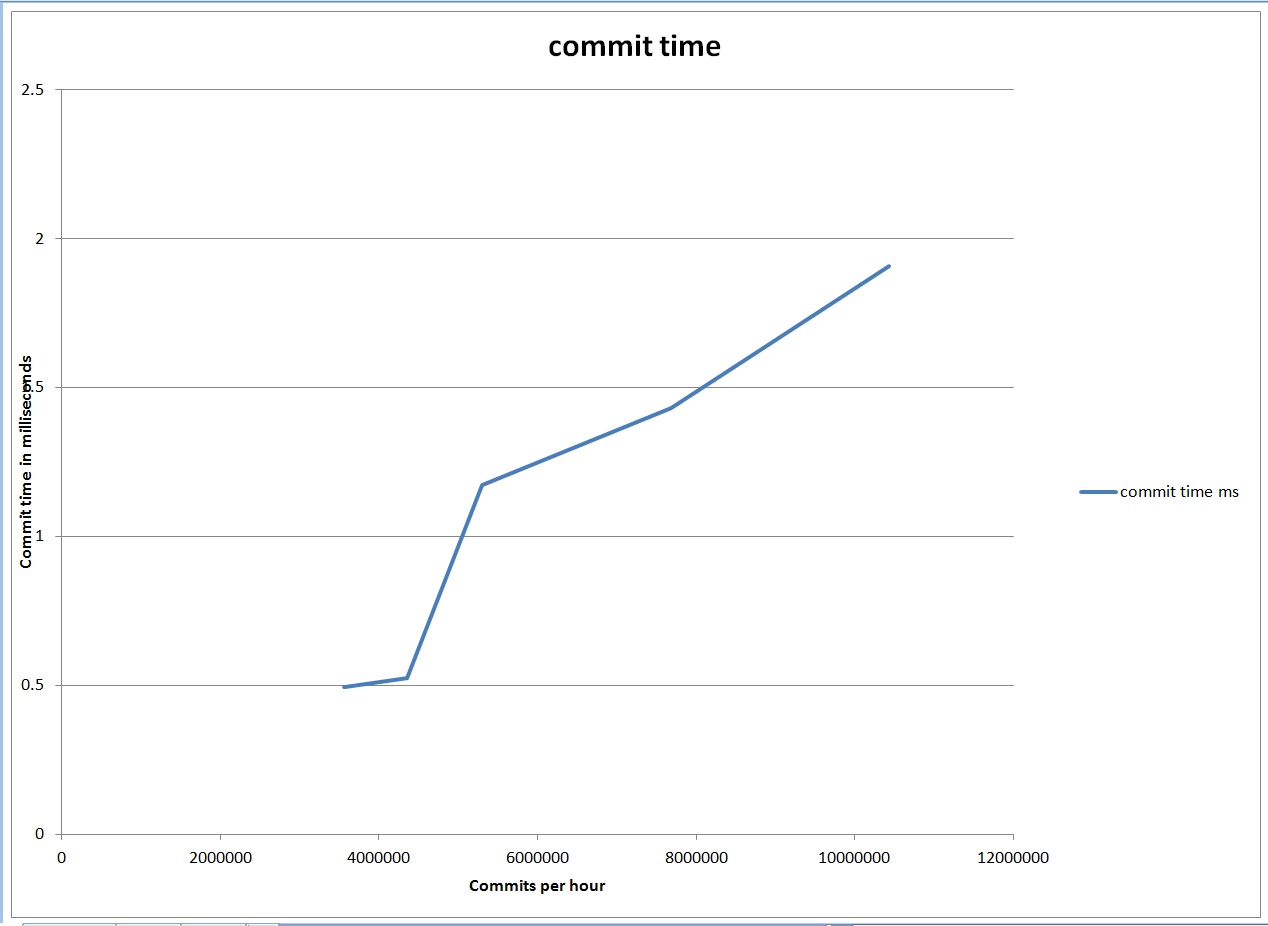
It started around half a millisecond at 3 million commits per hour and slowly grew to almost 2 milliseconds at 10 million commits per hour. So, commit time grew, but nothing like the original response time graph which went through the roof at around 3.6 million writes to the redo logs per hour.
Here is a zip of the scripts I used to generate the data, the spreadsheets I used to make the charts, and the results from the tests: zip
To run the tests yourself enter your own username and password at the top of setup.sql, commits.sql, and report.sql. Run one of the five reports – run1.sh, run2.sh, run5.sh, run10.sh or run20.sh like this:
./run5.sh
Wait for the last process to finish outputting then run the report:
./report.sh
Results look like this:
WAIT_EVENT ELAPSED_SECS WAITS_PER_HOUR WAITS_PER_SECOND AVG_WAIT_MS AVG_WAIT_SEC ----------------------- ------------ -------------- ---------------- ----------- ------------ log file parallel write 542 3008922.51 835.811808 .648076577 .000648077 log file sync 542 5306207.38 1473.94649 1.1727226 .001172723
I’m really just getting started understanding how commits scale, but it was surprising to me how hard it was to get the rate of redo log writes high enough to cause the write time to increase due to queuing. I assume this is because the database batches commits together more efficiently that I expected, which makes commits more scalable than I realized.
– Bobby
P.S. This is on HP-UX 11.31, Itanium, Oracle 11.2.0.3.0

Hello Bobby,
I use to follow this blog every day…I am going to do test in 10g&11g….thanks..
Thank you for your comment. If you get a chance let me know how your tests come out. I’m still trying to understand commit times I’m seeing in a busy production database and need to learn more about what affects commit time so any input I can get would be appreciated.