
In my forum discussion about free buffer waits I came across a term that I didn’t understand: “inode lock contention”. I’m pretty sure I had seen this same term years ago on one of Steve Adams’ pages on IO. But, I didn’t really understand what the term meant and so it was hard to understand whether this was something I was seeing on our production system that was experiencing “free buffer waits”.
First I had to figure out what an inode was. I knew that it had something to do with the way Unix filesystems work but reading this article(NO LONGER EXISTS) really helped clear up what inodes are at least on HP-UX. Inodes are small chunks of bytes that are used to define a Unix filesystem. On HP-UX’s VxFS filesystems a type 1 inode can point to up to 10 extents of one or more contiguous 8K blocks on a large filesystem. The filesystem I’ve been testing on appears to have 32 meg extents if I’m reading this output from lvdisplay correctly:
LV Size (Mbytes) 1472000 Current LE 46000
Total size of 1,472,000 meg divided by 46,000 logical extents = 32 meg per extent.
Since the inode can point to 1 to 10 extents it could point to between 32 and 320 meg.
My test case had 15 tables that were more than 1 gigabytes each. It seems like each table should span multiple inodes so even if there is locking at the inode level it looks like it won’t lock the entire table at once. Still, it seems unlikely to me that every time a table is updated that reads from all the other parts of the table pointed to by the same inode are really blocked by an inode lock. Yet that is what this document(NO LONGER EXISTS) suggests:
“During a read() system call, VxFS will acquire the inode lock in shared mode, allowing many processes to read a single file concurrently without lock contention. However, when a write() system call is made, VxFS will attempt to acquire the lock in exclusive mode. The exclusive lock allows only one write per file to be in progress at a time, and also blocks other processes reading the file. These locks on the VxFS inode can cause serious performance problems when there are one or more file writers and multiple file readers.”
It uses the term “file” but I assume if you have a large file that has multiple inodes it means it will lock just the pieces associated with the one inode that points to the blocks that are being written. The article goes on to explain how you can use the “cio” option to enable concurrent IO and eliminate this inode contention preventing writers from blocking readers. But, I’ve been testing with just the direct IO options and not the cio option and seeing great results. So, would I see even better improvement with concurrent io?
I didn’t want to mess with our current filesystem mount options since testing had proven them to be so effective but I found that in glance, a performance monitoring tool like top, you have an option to display inode waits. So, I took a test that was running with direct IO and had 15 merge statements loading data into the same empty table at once and ran glance to see if there were any inode waits. There were not:
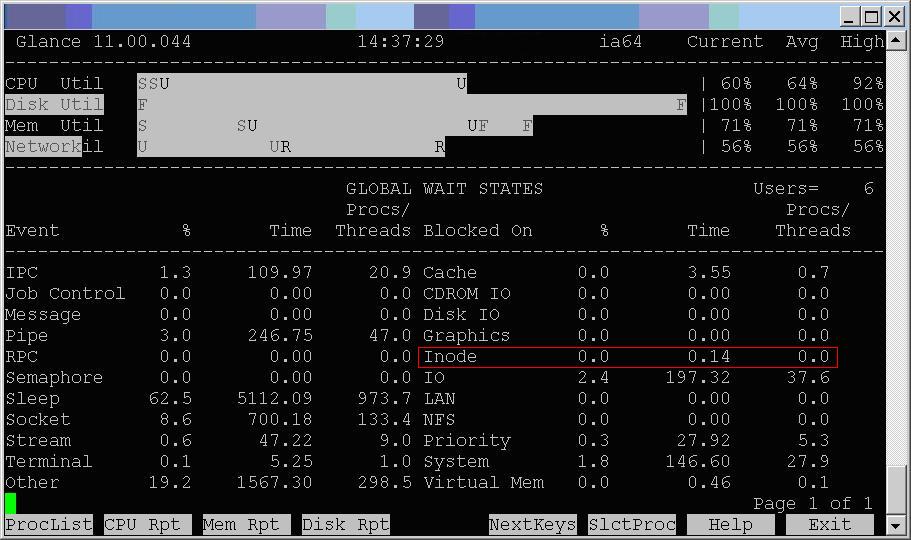
So, I don’t know if I can depend on this statistic in glance or not. It appears that the direct IO mount options are all we need:
mincache=direct,convosync=direct
filesystemio_options=DIRECTIO
There may be some case within Oracle 11.2.03 on HP-UX 11.31 where you can be hampered by inode lock contention despite having direct IO enabled but my tests have not confirmed it and I’ve banged pretty hard on my test system with a couple of different types of tests.
– Bobby

Just for completeness, see MOS How to use Concurrent I/O on HP-UX and improve throughput on an Oracle single-instance database [ID 1231869.1] for details of what not to do with cio.
Thanks for some informative testing!
Thanks for your comment. The Oracle document you cited was interesting.