
I haven’t figured out the best way to do this yet so this is a work in progress. I’m trying to document the process of taking a large query that joins many tables together and breaking it into a series of small queries that only join two tables at a time. Today I finished this process on a query that ran for four hours and the eleven queries I broke it up into together ran for five minutes. I did put a full and use_hash hint on one of the eleven queries.
Here is the process I followed:
- I started with permanent tables to save the intermediate results with the idea of making them global temporary tables with on commit preserve rows once I’d built all the new smaller queries.
- I worked on one join at a time. The query I worked on used the ANSI syntax for joins and had INNER and LEFT joins so I just worked in the order the tables were listed.
- The first temp table was the output of joining the first two tables. My query had twelve tables. Every temp table after that was the result of joining the latest temp table T1…T10 to the next real table.
- I included all of the columns in the select list and where clause from each real table I added to the join. I’m sure there is a better way to to this. Also, I took the table aliases like SLS and added them to the column names because there were columns of the same name from multiple tables. I.e. PROD_CODE became SLS_PROD_CODE because there might be a PDT_PROD_CODE from the table with the alias PDT.
- I inserted the final output into a table and compared it to the output from the original query to make sure they were exactly the same.
The weird thing about this in that there is no guarantee that joining tables in the order listed in the query will produce good results, but in this case it was much faster than running the entire query. It was kind of a one legged tree:
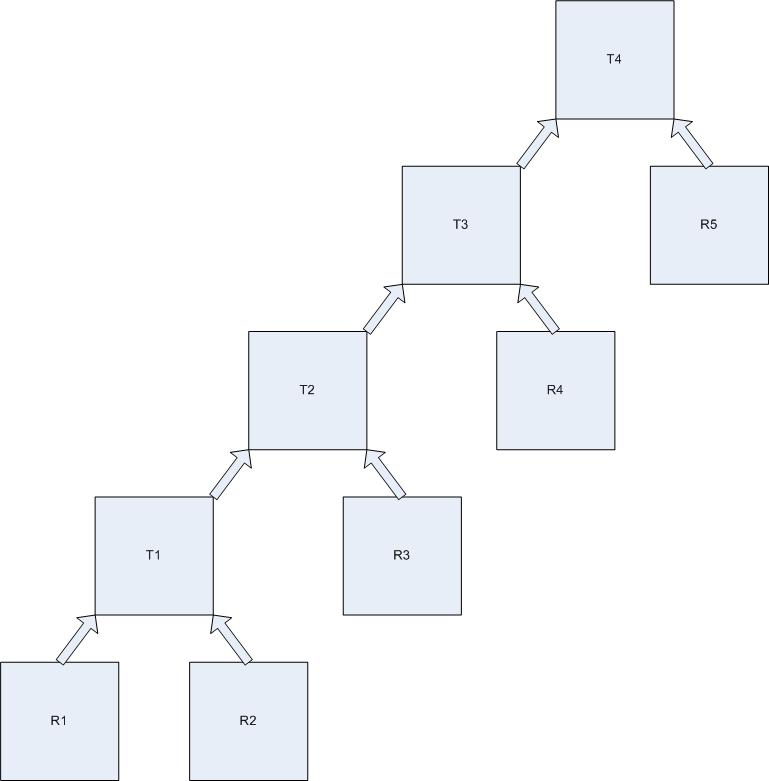
R1 through R5 represent my real tables from the original join. Really there where twelve of these.
T1 through T4 represent the global temporaries created with each join. In reality I had ten of these and the final output was inserted into a permanent table.
I don’t really know why breaking the query up into these small pieces was so effective but I do know that it would have taken a lot more work to try to make the bigger query run faster. It took time to split it up but it wasn’t difficult if you know what I mean. I was just tedious getting the list of column names edited together but that’s a lot easier than figuring out why the query with twelve tables joined together was taking four hours to run.
– Bobby

Why is this a good idea?
As a general rule, this is completely opposite to the general best performance approach which should be taken in Oracle which is to write one big query and then troubleshoot the efficiency of the execution plan.
Dom,
Thank you for your comment. It is easier for the optimizer to parse smaller queries and it is easier for humans to tune smaller queries. I’ve had a lot of success taking large queries that join many tables together and breaking them into smaller queries.
– Bobby