
I have been working hard on an issue that happened after we patched an Oracle database to the 19.13 patch set which just came out in October. The application experienced a ton of latch: shared pool waits, and the patch set had to be backed out. Currently the database is running on the 19.5 patch set and running fine. I have been trying to figure this out on my own and I have been working with Oracle support but so far, I have not come up with a proven resolution. But I thought I would document what I know here before I go off on vacation for two weeks around the Christmas and New Year holidays.
It all started on October 26th when we were still on 19.5 and our application hung up with alert log messages consistent with this bug:
Bug 30417732 – Instance Crash After Hitting ORA-00600 [kqrHashTableRemove: X lock] (Doc ID 30417732.8)
Here were the error messages:
One of these:
ORA-00600: internal error code, arguments: [kqrHashTableRemove: X lock], [0x11AA5F3A0]Then a bunch 0f these:
ORA-00600: internal error code, arguments: [kglpnlt]I found that the fix for bug 30417732 is in the 19.9 and later patch sets. So, I, perhaps foolishly, decided to apply the latest patch set (19.13) after testing it in our non-production databases. In retrospect I probably should have found a one-off patch for 30417732 but I wanted to catch up to the latest patch set and be on the current and hopefully most stable version of Oracle.
So after applying 19.13 in our lower environments and testing there we applied it on production on November 13th and we had poor performance in the application Monday through Thursday and finally backed out the patch set Thursday night. It has been fine ever since and the original problem, bug 30417732, has fortunately not happened again.
I generated an AWR report during an hour when the problem was occurring, and it showed latch: shared pool as the top foreground event. Like this:
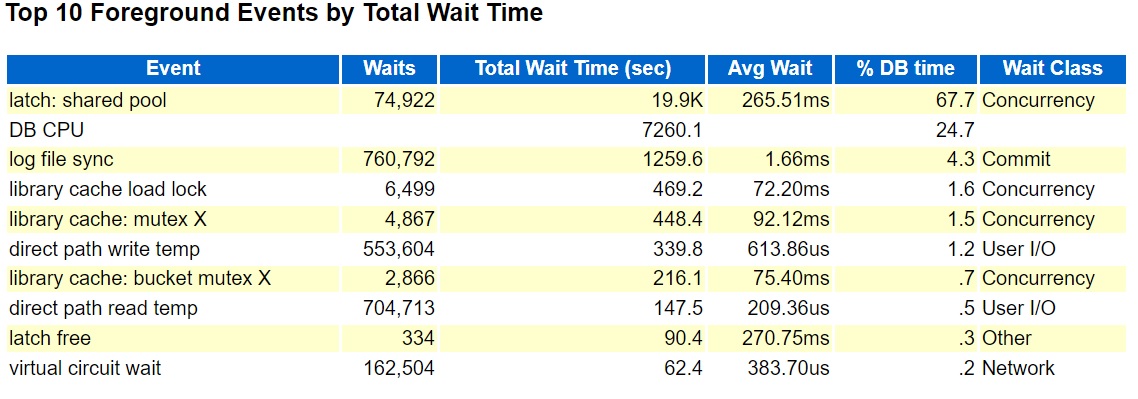
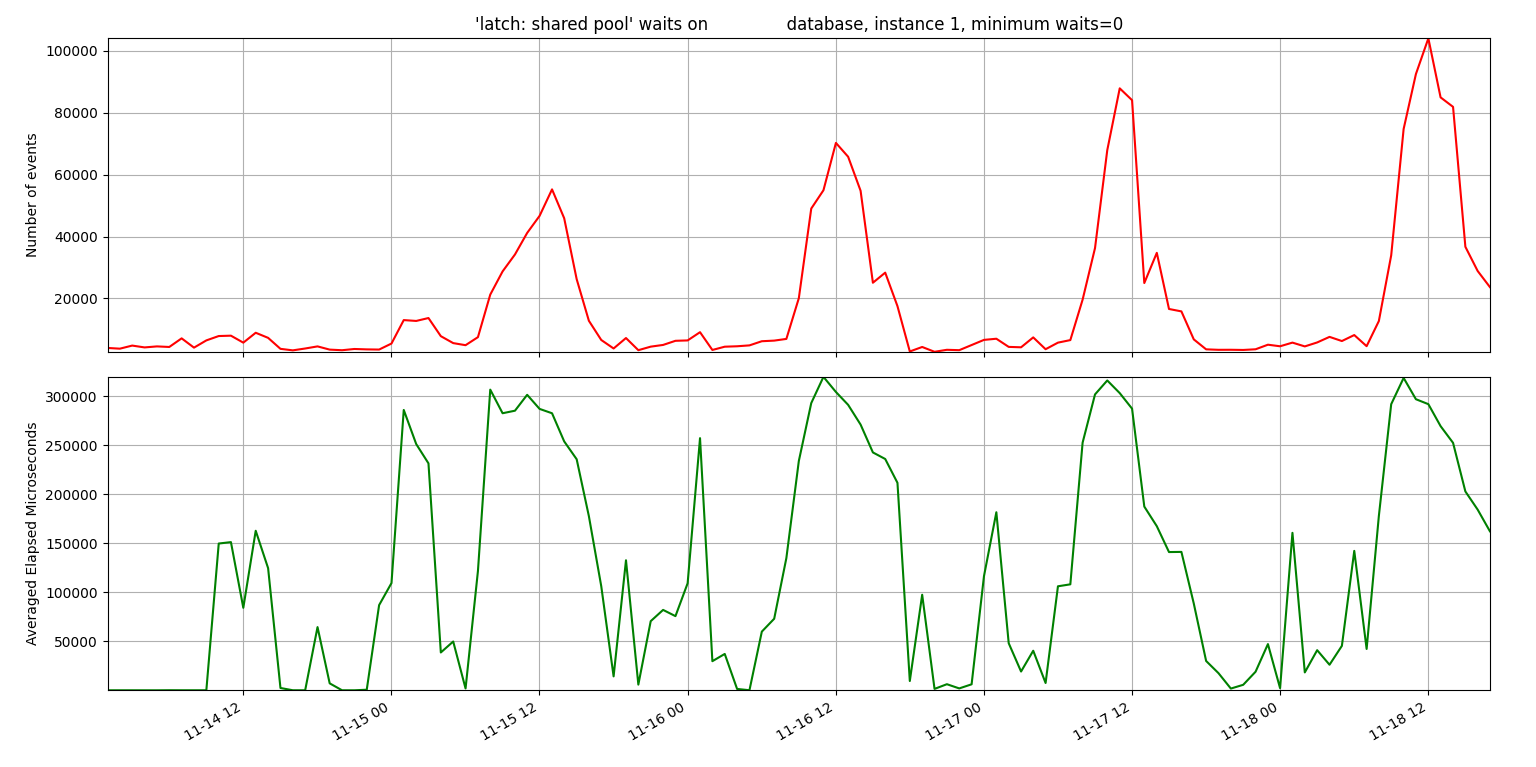
I was able to use my onewait.py and sessioncounts.py to show a correlation between the number of connected sessions and the number of latch waits.
Latch waits:
Number of connected sessions:
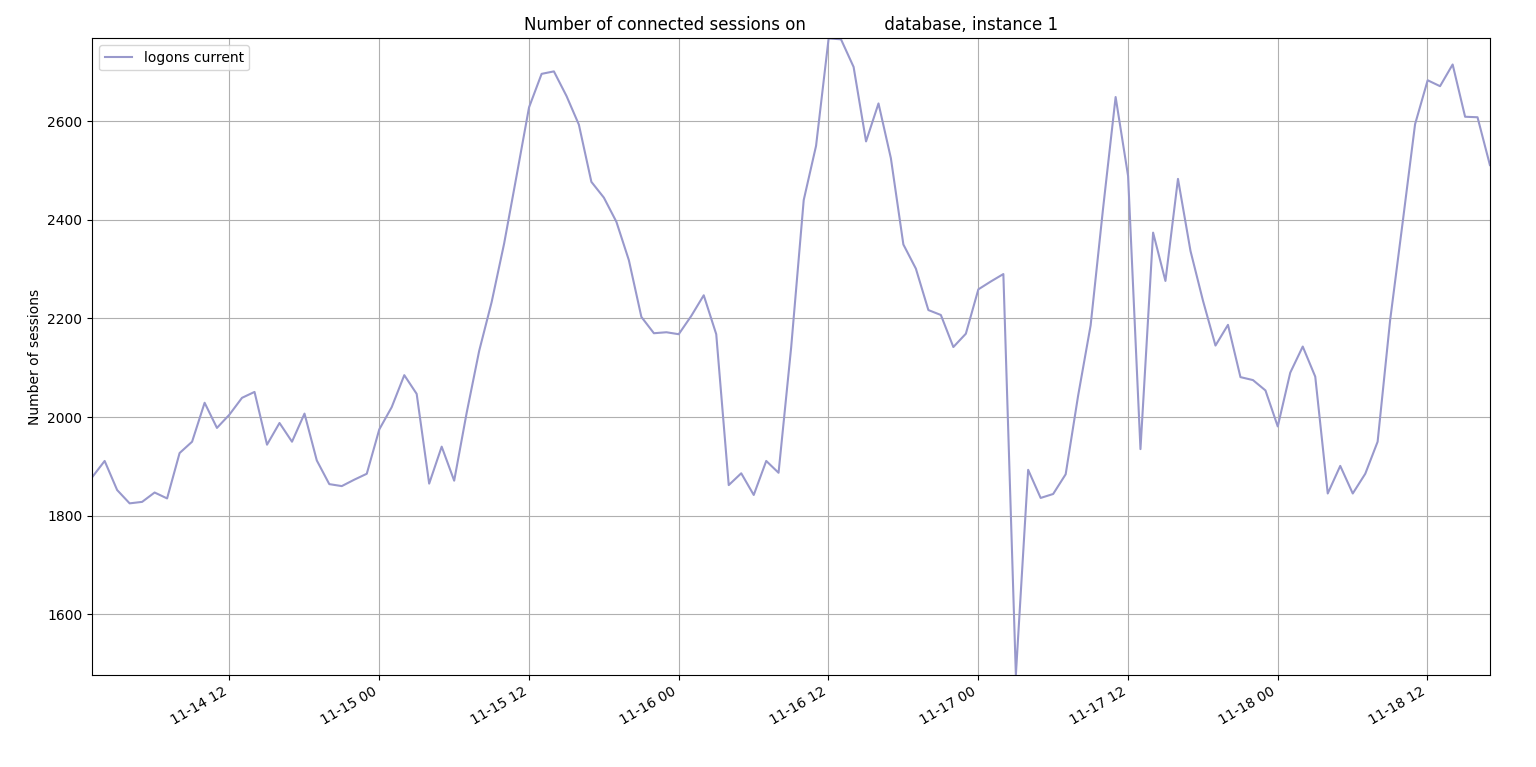
This database uses shared servers which uses memory in the shared pool and large pool so it makes sense that a bunch of logins might cause some contention for the shared pool. I tried to recreate the high latch: shared pool waits on a test database by running a Java script that just creates 1000 new sessions:
This did result in similar or even worse latch: shared pool waits during the time the Java script was running:
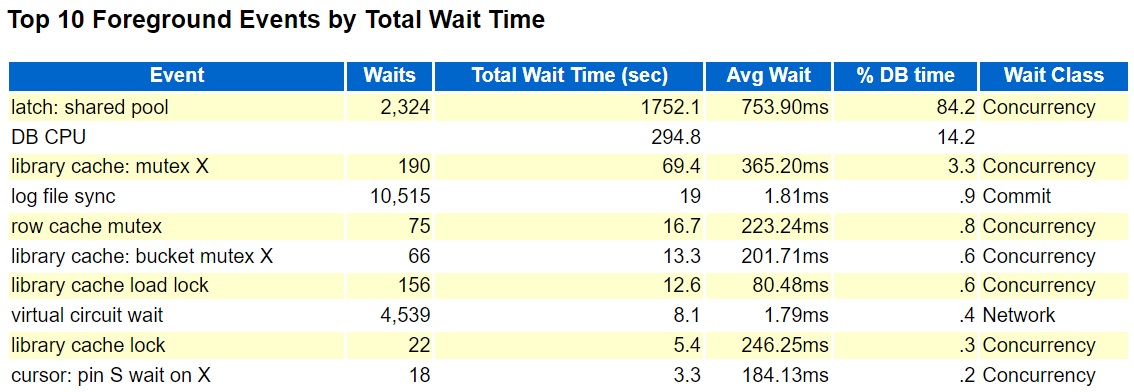
So, I have been able to recreate the problem in a test database but now I am stuck. This is not a minimal reproducible example. The test database is actively used for development and testing. I have tried to create my own load to apply to a small database but so far, I cannot reproduce the exact results. If I run 10 concurrent copies of MaxSessions.java I can get latch: shared pool waits on a small database, but I get the same behavior on 19.5 as I do on 19.13. So, something is missing. Here is a spreadsheet of my test results:
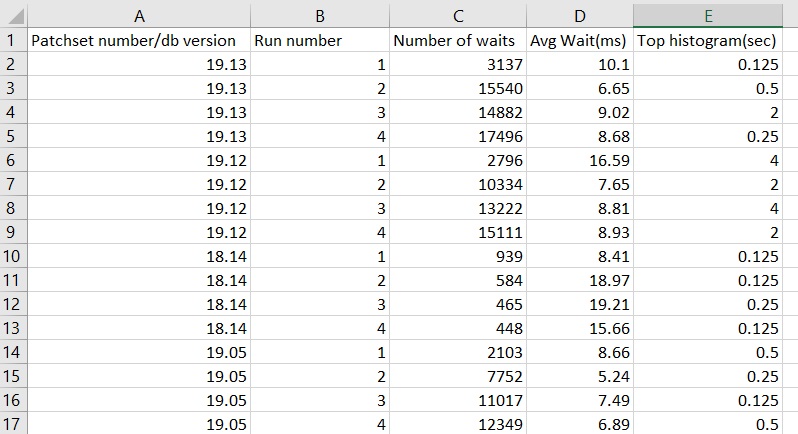
19.5, 19.12, and 19.13 have the same results but 18.14 is a lot better. I was trying to come up with a test that was a lot better on 19.5 than 19.13 but I have not succeeded.
I have looked at a boatload of other things not listed here but I am running out of steam. Friday is my last day working until January 4th, so I hope to put this out of my mind until then. But I thought it was worth using this blog post to document the journey. Maybe at some point I will be able to post a positive update.
Bobby
12/16/21
Made some progress working with Oracle support on this yesterday. I did not mention in this post that the latch behind all the latch: shared pool waits was
kghfrunp: alloc: waitHere is the top latch from the AWR report:

An Oracle analyst noted that this bug also involves the same latch:
Bug 33406872 : LATCH SHARED POOL CONTENTION AFTER UPGRADE TO 19.12
I had noticed bug 33406872 but I did not know that it was on the kghfrunp: alloc: wait latch because that information is not visible to Oracle customers.
The same analyst had me rerun the Java script listed above but with a dedicated server connection. I did and it did not have the latch waits. So, this is a shared server bug.
Oracle development is working on it so there is no fix yet but here is the situation as it seems to be now: If you are using shared servers on 19.12 or 19.13 and have high latch: shared pool waits on the kghfrunp: alloc: wait latch you may be hitting a new bug that Oracle is working on.
1/7/2022
After getting back from 2 weeks vacation I took another crack at this and I think I have come up with a useful test case for the SR. Time will tell, but it looks promising. I added a second Java script to the MaxSessions one listed above. Here it is:
This opens 1000 shared server sessions and then runs unique select statements on each of the 1000 sessions one at a time looping up to 1000 times. After about 60 loops I get the latch: shared pool waits. I tried this on both 19.13 and 19.5 and I get the waits in both but with differences.
19.13 after 100 loops:

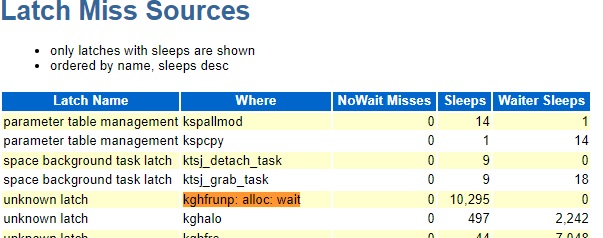
19.5 after 100 loops

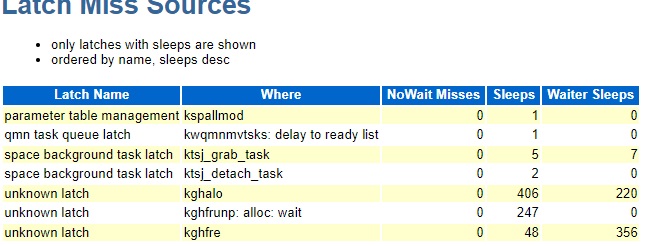
Avg Wait, % DB time, and sleeps for the kghfrunp: alloc: wait latch were all higher on 19.13.
Note that I had to keep the GenLoad.java script running while I ran MaxSessions.java and I took AWR snapshots around the MaxSessions run to get these AWR report outputs.
Maybe this will be enough to help Oracle recreate this behavior internally.
Bobby
10/24/22
Back from a weeklong cruise vacation and Oracle support says that they opened bug 33801843 for this issue and that it will be fixed in a future release. I would not use shared servers going forward after 19.11.
1/6/22
Good news. Oracle had me try my test case with 19.17 and it worked great. I tested with the December monthly patch set on top of 19.17 so I do not know exactly what fixed it. But, based on my tests applying 34419443 and 34819700 on 64-bit Linux resolves the issue described above which was introduced in 19.12.
Here are the zips I used to patch including latest OPatch:
$ ls -altr
total 1798904
drwxr-xr-x. 7 oracle dba 71 Sep 21 11:34 ..
-rw-rw-rw-. 1 oracle dba 1580330977 Jan 13 16:43 p34419443_190000_Linux-x86-64.zip
-rw-rw-rw-. 1 oracle dba 138029131 Jan 13 16:44 p34819700_1917000DBRU_Linux-x86-64.zip
-rw-rw-rw-. 1 oracle dba 123714997 Jan 13 16:47 p6880880_190000_Linux-x86-64.zip

Hi Bobby,
We also run 19.13 databases, some one AIX, some on Linux. Several days ago one of them froze on latches, mostly on ‘latch: shared pool’ and ‘latch: call allocation’, we had to restart the instance.
Oracle Support pointed to bug 33415279 that causes growth of ‘pga accounting’ component of share pool. We knew about the bug, ‘pga accounting’ was indeed growing. However the entire shared pool was growing: ‘free memory’ was growing, SQLA was growing, etc. Are you seeing growth of ‘pga accounting’ in your environment? This bug affected several non-prod databases, ‘pga accounting’ was growing, SQLA was shrinking, eventually the database would start reporting ORA-04031 and we had to restart, but we never observed latch waits.
After going through DBA_HIST_ACTIVE_SESS_HISTORY data I found that this database had a similar issue on May 01: the number of sessions waiting on ‘latch: shared pool’ went from zero to 1,000 in about one minute. Then the waits disappeared. DBA_HIST_MEMORY_RESIZE_OPS shows that the instance automatically added about 50 MB to the shared pool as soon as latch waits became significant. DB cache was reduced by the same amount. This database is running with SGA_TARGET = 0, still the resizing happened.
We use dedicated connections, normally the waits on ‘latch: shared pool’ are low. We tried to apply patch 33415279 online (README said that it could be applied online), it didn’t work. What’s you experience with online patches?
Thank you for your comment on my post. I only see the issues I am experiencing with shared servers so if you are seeing issues with dedicated server connections I have not seen that behavior. I have an open SR with Oracle and development is supposed to be working on the bug but so far the various patches they have suggested have not resolved the issue.
Bobby
Did you ever come up with a full fix for this?
We recently upgraded a database from 12.1 to 19.13 which also uses shared servers. Occasionally we are getting a hanging situation exactly like you describe. Having a hard time figuring out what it is because it only lasts about a minute and attempts to to hanganalyze etc are not able to gather the needed information for support
Scott,
I have an SR open since December on this and no solution. If they come up with something I will update this blog post but I’m afraid that you may need to back out your upgrade or move away from shared servers. You could try an earlier 19c patch set set like 19.5.
Bobby
Think we ended up finding our issue. We will know for sure tomorrow morning. We had an app using a 12.1 jdbc driver which was throwing 10s of 1000’s of parse errors. The statement that was throwing the errors was not in the app it was being done by the jdbc driver for some reason and it did not return the parse error to the app. The only reason we knew about it was the alert log in 19 has parse error warnings
The driver was upgraded on thursday morning and we havent had an issue since. Tomorrow will be the real test though
Sounds like a different issue than mine which is a good thing for you! I hope it works out.
Bobby
Saw the other responses today and figured I would come back and update this on our situation which was finally resolved though it took a few iterations to get to.
The JDBC driver I mentioned was not the root cause but it was not helping the situation and after we resolved that issue the ‘hangs’ were not happening as often.
We ended up going from these intermittent hangs that lasted a few minutes to constant ora-4031’s eventually.
Oracle support asked us to do to 2 things.
1) Increase shared pool reserved to 20% of SGA. This removed the hangs that we were hitting but they all turned into ora-4031 errors. the interesting thing was that there was a large portion of the SGA that was free
2) The second thing and ultimately what fixed our issue was unsetting shared_pool_size in the PDB. As soon as this was removed all the ora-4031 errors went away and have not returned.
There is a support note that says they recommend not setting it at the PDB level only at the CDB. We missed that. They did say that memory was not being managed properly but they would not say it was a bug.
Thank you for your follow up. It is a different issue from ours but I think it is helpful to have you document your solution here.
Was this issue resolved, we are now on 24 January 2024?
Just checking if it got resolved.
Yes. It seems to have been resolved in 19.17. I tested it with 19.17 and the December monthly patch set and it didn’t have the problem. Took over a year to get to this point.