
I am working on upgrading an Oracle database from 11.2.0.4 to 19c and migrating it from HP Unix to Linux. This 15-terabyte database is too large to copy from the old to the new system during our normal weekend downtime window. It also has a ton of weekend batch updates that overlap the normal weekend change window so it would be best for our business processing if the cut over from the old to the new system was as fast as possible.
I want to use GoldenGate to minimize the downtime for the cutover using an approach similar to what is described in this Oracle document:
Zero Downtime Database Upgrade Using Oracle GoldenGate
You start GoldenGate collecting changes on the current production system and then take your time copying the 15 TB of data from the old to new system. Once you are done with the initial load you apply the changes that happened in the meanwhile. Finally, you cut over to the new system. You could even switch the direction of the replication to push changes on the new production system back to the old system to allow for a mid-week back out several days after your upgrade. Pretty cool. A teammate of mine successfully used this approach on an important database some years back.
But the database that I am working on now, unlike the one that my colleague worked on, has a lot of tables set to nologging. Under the right conditions inserts into tables set to nologging are not written to the redo logs and will be missed by GoldenGate. This Oracle article recommends setting your database to FORCE LOGGING so GoldenGate will not miss any updates:
In order to ensure that the required redo information is contained in the Oracle redo logs for segments being replicated, it is important to override any NOLOGGING operations which would prevent the required redo information from being generated. If you are replicating the entire database, enable database force logging mode.
Oracle GoldenGate Performance Best Practices
We could also switch all our application tables and partitions in the source system to logging but we have so many I think we would set the whole database to force logging.
But the big question which I touched on in my previous post is whether force logging will slow down our weekend batch processing so much that we miss our deadlines for weekend processing to complete and affect our business in a negative way. The more I investigate it the more convinced I am that force logging will have minimal impact on our weekend jobs. This is an unexpected and surprising result. I really thought that our batch processing relied heavily on nologging writes to get the performance they need. It makes me wonder why we are using nologging in the first place. It would be a lot better for backup and recovery to have all our inserts logged to the redo logs. Here is a nice Oracle Support document that lays out the pros and cons of using nologging:
The Gains and Pains of Nologging Operations (Doc ID 290161.1)
I have an entry in my notes for this upgrade project dated 8/26/19 in which I wrote “Surely force logging will bog the … DB down”. Now I think the opposite. So, what changed my mind? It started with the graph from the previous post:
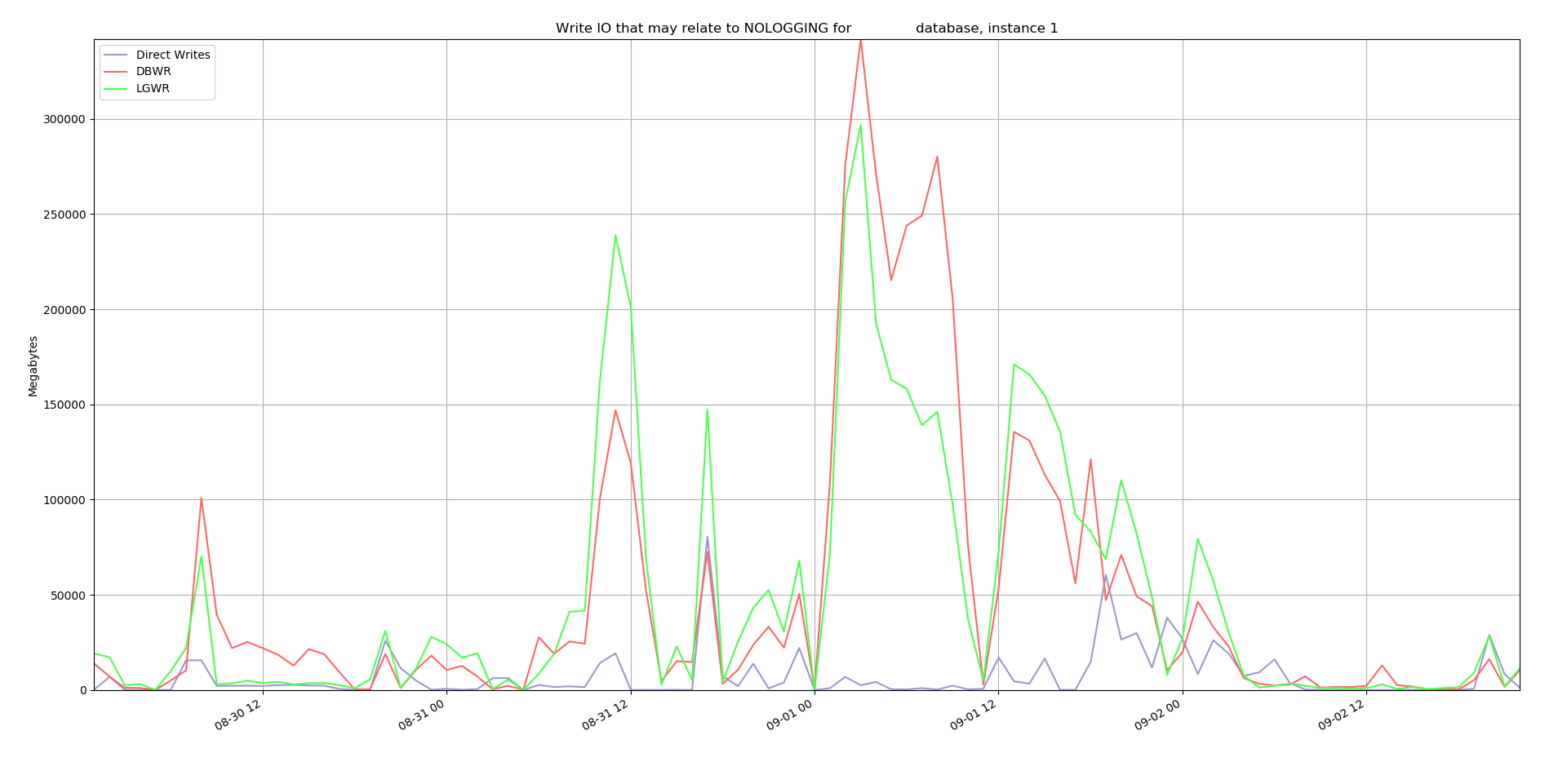
I was really surprised that the purple line was so low compared to the other two. But I felt like I needed to dig deeper to make sure that I was not just misunderstanding these metrics. The last thing I want to do is make some production change that slows down our weekend processes that already struggle to meet their deadlines. I was not sure what other metrics to look at since I could not find something that directly measures non-logged writes. But then I got the idea of using ASH data.
In my “Fast way to copy data into a table” post I said that to copy data quickly between two Oracle tables “you want everything done nologging, in parallel, and using direct path”. I may have known then and forgotten but working on this now has me thinking about the relationship between these three ways of speeding up inserts into tables. I think there are the following two dependencies:
- Nologging requires direct path
- Parallel requires direct path
Oracle document “Check For Logging / Nologging On DB Object(s) (Doc ID 269274.1)” says the first one. In the second case if you have a target table set to parallel degree > 1 and you enable parallel DML you get direct path writes when you insert into the target table.
From all this I got the idea to look for direct path write waits in the ASH views. I could use ASH to identify insert statements that are using direct path. Then I could check that the target tables or partitions are set to nologging. Then I would know they are doing non-logged writes even if I did not have a metric that said so directly.
directwritesql.sql looked at all the SQL statements that had direct write waits over the entire 6 weeks of our AWR history. The output looks like this:
select
2 sql_id,count(*) active
3 from DBA_HIST_ACTIVE_SESS_HISTORY a
4 where
5 event = 'direct path write'
6 group by sql_id
7 order by active desc;
SQL_ID ACTIVE
------------- ----------
2pfzwmtj41guu 99
g11qm73a4w37k 88
6q4kuj30agxak 58
fjxzfp4yagm0w 53
bvtzn333rp97k 39
6as226jb93ggd 38
0nx4fsb5gcyzb 36
6gtnb9t0dfj4w 31
3gatgc878pqxh 31
cq433j04qgb18 25
These numbers startled me because they were so low. Each entry in DBA_HIST_ACTIVE_SESS_HISTORY represents 10 seconds of activity. So over 6 weeks our top direct path write waiter waited 990 seconds. Given that we have batch processes running full out for a couple of days every weekend 990 seconds over 6 weekends is nothing.
I took the top SQL ids and dumped out the SQL text to see what tables they were inserting into. Then I queried the LOGGING column of dba_tables and dba_tab_partitions to see which insert was going into a table or partition set to nologging.
select logging,table_name
from dba_tables
where owner='MYOWNER' and
table_name in
(
... tables inserted into ...
)
order by table_name;
select logging,table_name,count(*) cnt
from dba_tab_partitions
where table_owner='MYOWNER' and
table_name in
(
... tables inserted into ...
)
group by logging,table_name
order by table_name,cnt desc;This simple check for LOGGING or NOLOGGING status eliminated several of the top direct path write waiters. This process reduced the list of SQL ids down to three top suspects:
SQL_ID ACTIVE
------------- ----------
cq433j04qgb18 25
71sr61v1rmmqc 17
0u0drxbt5qtqk 11
These are all inserts that are not logged. Notice that the most active one has 250 seconds of direct path write waits over the past 6 weeks. Surely enabling force logging could not cause more than about that much additional run time over the same length of time.
I got the idea of seeing what percentage of the total ASH time was direct path write waits for each of these SQL statements. In every case it was small:
cq433j04qgb18
TOTAL_SAMPLE_COUNT DW_SAMPLE_COUNT DW_SAMPLE_PCT
------------------ --------------- -------------
2508 25 .996810207
71sr61v1rmmqc
TOTAL_SAMPLE_COUNT DW_SAMPLE_COUNT DW_SAMPLE_PCT
------------------ --------------- -------------
1817 17 .935608145
0u0drxbt5qtqk
TOTAL_SAMPLE_COUNT DW_SAMPLE_COUNT DW_SAMPLE_PCT
------------------ --------------- -------------
8691 11 .126567714
TOTAL_SAMPLE_COUNT was all the samples for that SQL_ID value for the past 6 weeks. DW_SAMPLE_COUNT is the same count of samples that are direct write waits that we already talked about. DW_SAMPLE_PCT is the percentage of the total samples that were direct write wait events. They were all around 1% or lower which means that write I/O time was only about 1% of the entire run time of these inserts. The rest was query processing best I can tell.
Also I used my sqlstat script to look at the average run time for these inserts:
These queries run at most a couple of hours. If direct path writes are 1% of their total run time, I estimated that force logging would add about 1% to the elapsed time or about 2 minutes per execution.
The final step was to try to run one of these top nologging I/O inserts in a test environment with and without force logging to see if the test matches the expected performance slowdown. I was not able to run 0u0drxbt5qtqk without setting up a more elaborate test with the development team. My test of cq433j04qgb18 ran considerably faster with force logging than without it so I think other factors were hiding whatever effect force logging had. But 71sr61v1rmmqc had some nice results that matched my estimates well. This is on a Delphix clone of production so the data was up to date with prod but the underlying I/O was slower.
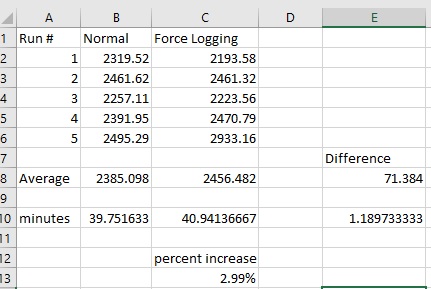
The individual run times are in seconds and the averages are listed in seconds and in minutes. I ran the insert 5 times with no force logging and 5 times with it alternating. I dropped the primary key and unique index of the target table to keep from getting constraint errors. I rolled back the insert each time. It averaged about 1.2 minutes more out of 40 minutes of run time which is about a 3% increase. My estimate from ASH was about 1% so this test matches that well.
The final test remains. In some upcoming production weekend, I will put in a change to flip the database to force logging and see how it goes. My tests were run on a test system with a different storage system and with no other activity. We might see different results on a heavily loaded system with a queue for the CPU. But, after all this analysis and testing I feel confident that we won’t be able to tell that force logging is enabled. Unfortunately, we sometimes have performance issues anyway due to plan changes or data volume so the force logging switch might get blamed. But I feel confident enough to push for the final test and I think we ultimately will pass that test and be able to use force logging to enable GoldenGate to support a short cut over time for our migration and upgrade project.
Bobby
P.S. A good question came in as a comment about direct path write waits and asynchronous I/O. The system I am testing on does not support async I/O because it is HP Unix and a filesystem. This older blog post talks a bit about async and direct I/O on HP-UX:
So, your mileage may vary (YMMV) if you do these same queries on a system with asynchronous writes. Linux filesystems support async writes and on HP-UX our RAC system on ASM supports it. It is one of the challenges of writing blog posts. Other people may be in different situations than I am.

Hello,
I have trouble with nologging also.
2 queries I rely on to tell me if I’m really, really using NOLOGGING
SELECT file#, status, unrecoverable_change#, unrecoverable_time, substr(name, (LENGTH(name) – 59), 60) as NAME
FROM v$datafile
ORDER BY unrecoverable_time ASC NULLS FIRST, file#
/
and
SELECT *
FROM v$database_block_corruption
ORDER BY 1, 2, 3
/
If they come back with nothing I assume NOLOGGING has been overridden.
The different levels you can set nologging/force logging at, especially in CDB/PDB makes it tricky.
Regards,
Frank
Thanks for your comment and the helpful queries.
Bobby
Bobby,
A thought to bear in mind – with direct path writes Oracle can dispatch many writes asynchronously and end up showing only one or two or even zero) waits because of the way it then loops through the batch to see which ones it needs to wait for. If you check a trace file for a big direct path write you may find a very small number of waits that don’t sum their “blocks written” to the actual total number of blocks you know you’ve copied. This means the ASH sample could suggest you don’t do much I/O while at the same time the direct I/O is hammering the discs to death.
Frits Hoogland has a number of blog notes explaining the effects in detail, but I don’t have a link available at the moment.
Thanks for your comment Jonathan. I will look into this further. I did some testing of direct writes with and without force logging and did some traces but was not aware of direct writes being asynchronous. I recall something like this for direct path read wait events where the wait time does not add up to the real time but I don’t know if it is due to the same reasons. Thanks again for pointing this out. I will do some additional testing and track down Frits Hoogland’s blog posts on the subject.
Bobby
Jonathan,
I updated my post with information about your comment. My system is HP Unix using a filesystem so it does not support asynchronous I/O. But people who read this post may be on a system that does support it and they may be lead astray using the approach I am using. I tried to address this concern in my PS.
I did a trace and verified that the elapsed time and blocks for the direct path writes all add up to the expected values on my test system. Then I recalled that I had looked at asynchronous writes and HP Unix filesystems in the past.
Thanks again.
Bobby
I have done a very large DB migration in the past using standby to multi sites , then manually syncing standby as needed, Rolling a Standby Forward using an RMAN Incremental Backup To Fix The Nologging Changes (Doc ID 958181.1), would show you have to roll forward the ‘pseudo’ standby from a nologging, this way you could migrate db very fast and no extra cost.
(though in my case source db was in force logging mode, I see no reason why using inc backup you could not do same. The upgrade would need to be done after, also any issues with this you can use restore points to roll db back and perform migration another w/e.
Thanks for your comment. Would Dataguard work cross platform? The source is HP-UX Itanium and the target is Linux x64.
I was thinking of using the cross platform transportable tablespace approach if I could not use force logging and ggs:
V4 Reduce Transportable Tablespace Downtime using Cross Platform Incremental Backup (Doc ID 2471245.1)
I think that is the same idea because you use incremental RMAN backups to push the nologging updates to the target.
It works cross platform because it is TTS and not a full database replication using DG.
Bobby
Yes you could you TTS cross endian platform and incremental backups my colleague has done such a migration from x86 to sparc, but it was more error prone and needed a lot more testing to get right, the method I used for migration using a pseudo standby was cross platform but same endian and fairly straight forward, obviously GG costs when you can do it for free, also the standby method or TTS was done to multi geographical sites for VLDB and I could sync up with a final backup on golive day in minutes…….. as above any backout once open the standby could be undone using restore point if for any reason golive failed.
Thanks again for your comments. Very neat. In our case we already have GGS on this database and it is a different endian platform moving from HP-UX Itanium to Linux X86-64. We never have gotten going on Dataguard for anything but maybe that is because we do so much GGS.
Bobby
Yes, at GM we use the GoldenGate database migration all the time. It is our defacto method as it works so well and gives us virtually 0 time database switchovers.
Thanks for your comment. I have left force logging in place for a couple of weeks now with no effect on performance so I think we are set to use GoldenGate with this one. We use GGS for a variety of things but not for migrations as much. Probably we should use it more, especially for larger databases.
Bobby
Pingback: So Far So Good with Force Logging | Bobby Durrett's DBA Blog