
Last week I was asked to help with a performance problem that looked a lot like a problem I fixed in July with a SQL Profile. The query whose plan I fixed back in July was modified by a minor application change over the weekend. A single column that was already in the select clause was added to another part of the select clause. As a result, the SQL_ID for the new query was different than the one for the July query. The SQL Profile from July associated SQL_ID 2w9nb7yvu91g0 with PLAN_HASH_VALUE 1178583502, but since the SQL_ID was now 43r1v8v6fc52q the SQL Profile was no longer used. At first, I thought I would have to redo the work I did in July to create a SQL Profile for the new query. Then I realized that the plan I used in July would work with the new SQL_ID so all I did was create a SQL Profile relating SQL_ID 43r1v8v6fc52q with PLAN_HASH_VALUE 1178583502 and the problem was solved. This is an 11.2.0.3 database running on the HP-UX Itanium platform. Here is a post from 2013 explaining how to create a SQL Profile: url. I thought it would be helpful to use this post to go over the steps that I went through with the July incident and how I originally generated the good plan. Then I wanted to make some comments about the various ways I come up with good plans for SQL Profiles by either generating a new better plan or by finding an older existing better one. Lastly, I wanted to talk about how a given good plan can be used for a variety of similar SQL statements.
The problem query that I worked on in July and many of the other SQL statements that I tune with SQL Profiles have bind variables in their where clauses. Usually the optimizer generates the plan for a query with bind variables once based on the values of the bind variables at that time. Then, unless the plan is flushed out of the shared pool, the query continues to run on the same plan even if it is horribly inefficient for other bind variable values. There is a feature that will cause the optimizer to run different plans based on the bind variable values in some cases but the SQL statements that I keep running into do not seem to use that feature. Since the query I worked on in July had bind variables I assumed that it was a typical case of a plan that worked well for one set of bind variables and that was terribly slow for another set. So, I had to find a set of bind variable values that made the query slow and figure out a better plan for those values. I used my bind2.sql script to extract the bind variable values for the problem query when I was working on the problem in July.
After extracting the bind variables, I used an AWR report to figure out which part of the plan contributed the most to the run time of the query so that I knew which bind variable value was causing the slowdown. Using an AWR report in this way only works if you do not have a bunch of slow SQL statements running at the same time. In this case the problem query 2w9nb7yvu91g0 was dominating the activity on the database with 62.19% of the total elapsed time. If there were a bunch of SQL Statements at the top of this list with similar percent of total values, it might be hard to use the AWR report to find information about this one query.
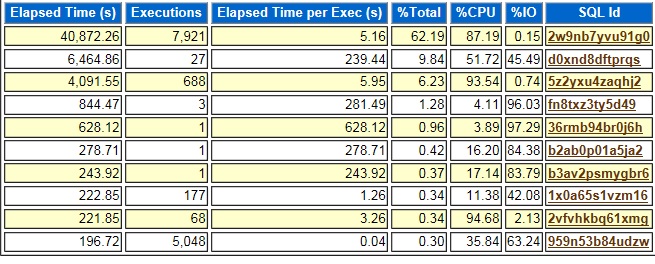
Since the activity for 2w9nb7yvu91g0 was 87.19% CPU I looked for the segments with the most logical reads. Logical reads are reads from memory, so they consume CPU and not disk I/O. In the graph below the segment for the S_ACCNT_POSTN table has 88.60% of the logical reads so most likely this segment caused the slowness of the query’s plan.
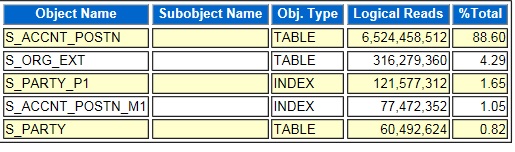
I looked at the plan for 2w9nb7yvu91g0 to see where the most heavily read table was used. This would probably be the source of the slow query performance. I found that it was doing a range scan of an index for the S_ACCNT_POSTN table that had the column POSITION_ID as its first column. This made me suspect that the plan was using the wrong index. If an index was used to retrieve many rows from the table that could take a long time. I did a count on all the rows in the table grouping by POSITION_ID and found that most rows had a specific value for that column. I replaced the actual POSITION_ID values with VALUE1, VALUE2, etc. below to hide the real values.
POSITION_ID CNT
--------------- ----------
VALUE1 2075039
VALUE2 17671
VALUE3 8965
VALUE4 5830
VALUE5 5502
VALUE6 5070
VALUE7 4907
VALUE8 4903Next, I verified that the query had an equal condition that related a bind variable to the POSITION_ID column of the problem table. This made me suspect that the plan in the shared pool was generated with a bind variable value for POSITION_ID other than VALUE1. So, that plan would work well for whatever value was used to create it. POSITION_ID would be equal to that value for a small percentage of the rows in the table. But, running the query in SQL*Plus with POSITION_ID=’VALUE1′ caused the optimizer to choose a plan that made sense given that this condition was true for most of the rows in the table. The PLAN_HASH_VALUE for the new plan was 1178583502.
I tested 1178583502 against a variety of possible bind variable values by using an outline hint in SQL*Plus scripts to force that plan no matter which values I tested against. I extracted the outline hint by running the query with POSITION_ID=’VALUE1′ and using this dbms_xplan call:
select * from table(dbms_xplan.display_cursor(null,null,'OUTLINE'));Then I just added the outline hint to a copy of the same SQL*Plus script and tried various combinations of bind variable values as constants in the where clause just as I had tried VALUE1 for POSITION_ID. I used the values that I had extracted using bind2.sql. After verifying that the new plan worked with a variety of possible bind variable values, I used a SQL Profile to force 2w9nb7yvu91g0 to use 1178583502 and the problem was resolved.
I have just described how I created the original July SQL Profile by running a version of the problem query replacing the bind variables with constants that I knew would cause the original plan to run for a long time. The optimizer chose a better plan for this set of constants than the one locked into the shared pool for the original query. I used the PLAN_HASH_VALUE for this plan to create a SQL Profile for the July query. This is like an approach that I documented in two earlier blog posts. In 2014 I talked about using a hint to get a faster plan in memory so I could use it in a SQL Profile. In 2017 I suggested using an outline hint in the same way. In both of those cases I ran the problem query with hints and verified that it was faster with the hints. Then I used a SQL Profile to force the better PLAN_HASH_VALUE onto the problem query. So, in all these cases the key is to generate a better plan in any way possible so that it is in memory and then create a SQL Profile based on it. A lot of times we have queries that have run on a better plan in the past and we just apply a SQL Profile that forces the better plan that is already in the system. My December, 2018 post documents this type of situation. But the 2014 and 2017 blog posts that I mentioned above and the July 2018 example that I just described all are similar in that we had to come up with a new plan that the query had never used and then force it onto the SQL statement using a SQL Profile.
The incidents in January and July and the cases where I added hints all lead me to wonder how different one SQL statement can be from another and still share the same plan. The problem last week showed that two queries with slightly different select clauses could still use the same plan. The other cases show that you can add hints or run the statement with bind variables replaced with constants. In the January case I did not have to go back through the analysis that I did in July because I could quickly force the existing plan from the July query onto the January one. The January problem also shows the limits of SQL Profiles. The slightest change to a SQL statement causes a SQL Profile to be ignored, even though the plan would still work for the new SQL statement. But in the January case the ability to use the same plan for slightly different queries made it easy to create a new SQL Profile.
Bobby

Hi. Bobby. Great as always. I’d like to know if that behavior relate to bind variables and using sqlprofiles will be the same using SPM. thanks in advance
Thanks for your comment. I think that the idea with SQL Plan Management is to lock in the existing good plans. If you have a SQL statement with bind variables that have the kind of problem I described in the post I think you would have to be sure that you created the plan with the right set of bind variable values before capturing the plan in a baseline. In the situation that we had in production in July and last week the performance on the system was terrible so you would not capture a baseline until you resolved that kind of issue.
Bobby