
A project team asked me to look at the performance of an Oracle database application that does a bunch of inserts into a table. But, when I started looking at the AWR data for the insert the data confused me.
The SQL by elapsed time section looked like this:
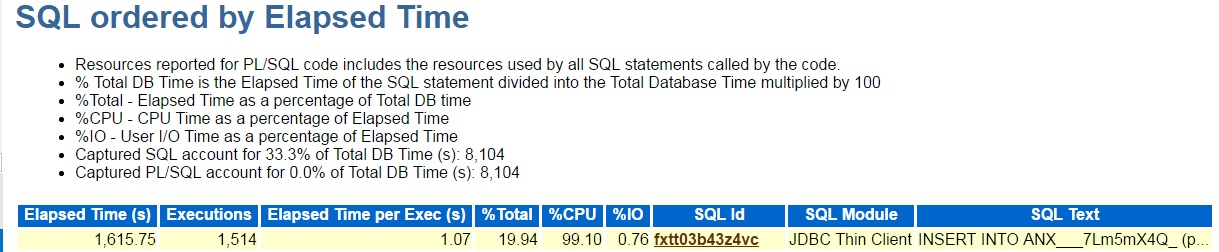
So, 1514 executions of an insert with 1 second of elapsed time each, almost all of which was CPU. But then I looked at the SQL text:
![]()
Hmm. It is a simple insert values statement. Usually this means it is inserting one row. But 1 second is a lot of CPU time to insert a row. So, I used my sqlstat.sql script to query DBA_HIST_SQLSTAT about this sql_id.
>select ss.sql_id, 2 ss.plan_hash_value, 3 sn.END_INTERVAL_TIME, 4 ss.executions_delta, 5 ELAPSED_TIME_DELTA/(executions_delta*1000) "Elapsed Average ms", 6 CPU_TIME_DELTA/(executions_delta*1000) "CPU Average ms", 7 IOWAIT_DELTA/(executions_delta*1000) "IO Average ms", 8 CLWAIT_DELTA/(executions_delta*1000) "Cluster Average ms", 9 APWAIT_DELTA/(executions_delta*1000) "Application Average ms", 10 CCWAIT_DELTA/(executions_delta*1000) "Concurrency Average ms", 11 BUFFER_GETS_DELTA/executions_delta "Average buffer gets", 12 DISK_READS_DELTA/executions_delta "Average disk reads", 13 ROWS_PROCESSED_DELTA/executions_delta "Average rows processed" 14 from DBA_HIST_SQLSTAT ss,DBA_HIST_SNAPSHOT sn 15 where ss.sql_id = 'fxtt03b43z4vc' 16 and ss.snap_id=sn.snap_id 17 and executions_delta > 0 18 and ss.INSTANCE_NUMBER=sn.INSTANCE_NUMBER 19 order by ss.snap_id,ss.sql_id; SQL_ID PLAN_HASH_VALUE END_INTERVAL_TIME EXECUTIONS_DELTA Elapsed Average ms CPU Average ms IO Average ms Cluster Average ms Application Average ms Concurrency Average ms Average buffer gets Average disk reads Average rows processed ------------- --------------- ------------------------- ---------------- ------------------ -------------- ------------- ------------------ ---------------------- ---------------------- ------------------- ------------------ ---------------------- fxtt03b43z4vc 0 29-SEP-16 07.00.34.682 PM 441 1100.68922 1093.06512 .32522449 0 0 .000492063 60930.449 .047619048 4992.20181 fxtt03b43z4vc 0 29-SEP-16 08.00.43.395 PM 91 1069.36489 1069.00231 .058494505 0 0 0 56606.3846 .010989011 5000 fxtt03b43z4vc 0 29-SEP-16 09.00.52.016 PM 75 1055.05561 1053.73324 .00172 0 0 0 55667.1333 0 4986.86667 fxtt03b43z4vc 0 29-SEP-16 10.00.01.885 PM 212 1048.44043 1047.14276 .073080189 0 0 .005287736 58434.6934 .004716981 4949.35377
Again it was about 1 second of cpu and elapsed time, but almost 5000 rows per execution. This seemed weird. How can a one row insert affect 5000 rows?
I found an entry in Oracle’s support site about AWR sometimes getting corrupt with inserts into tables with blobs so I thought that might be the case here. But then the dev team told me they were using some sort of app that did inserts in batches of 1000 rows each. I asked for the source code. Fortunately, and this was very cool, the app is open source and I was able to look at the Java code on GitHub. It was using executeBatch in JDBC to run a bunch of inserts at once. I guess you load up a bunch of bind variable values in a batch and execute them all at once. Makes sense, but it looked weird in the AWR.
Here is the Java test program that I hacked together to test this phenomenon:
import java.sql.*;
import oracle.jdbc.*;
import oracle.jdbc.pool.OracleDataSource;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.util.*;
public class InsertMil5k
{
public static void main (String args [])
throws SQLException
{
OracleDataSource ods = new OracleDataSource();
ods.setUser("MYUSER");
ods.setPassword("MYPASSWORD");
ods.setURL("jdbc:oracle:thin:@MYHOST:1521:MYSID");
OracleConnection conn =
(OracleConnection)(ods.getConnection ());
conn.setAutoCommit(false);
PreparedStatement stmt = conn.prepareStatement("insert into test values (:1,:2,:3,:4)");
byte [] bytes = new byte[255];
int k;
for (k=0;k<255;k++)
bytes[k]=(byte)k;
/* loop 200 times. Make sure i is unique */
int i,j;
for (j=0;j < 200; j++) {
/* load 5000 sets of bind variables */
for (i=j*5000;i < (j*5000)+5000; i++) {
stmt.setString(1, Integer.toString(i));
stmt.setInt(2, 1);
stmt.setBinaryStream(3, new ByteArrayInputStream(bytes), bytes.length);
stmt.setLong(4, 1);
stmt.addBatch();
}
stmt.executeBatch();
conn.commit();
}
conn.close();
}
}
I started with one of the Oracle JDBC samples and grabbed the batch features from the github site. I just made up some random data which wasn’t super realistic. It took me a while to realize that they were actually, at times, doing 5000 row batches. The other AWR entries had 1000 rows per execution so that finally makes sense with what the dev team told me.
I guess the lesson here is that the AWR records each call to executeBatch as an execution but the number of rows is the size of the batch. So, that explains why a simple one row insert values statement showed up as 5000 rows per execution.
Bobby
P.S. The other thing that I didn’t mention when I wrote this blog post of Friday was my confusion over the number of buffer gets. If you look at the sqlstat output above you will see around 60,000 buffer gets per execution. This really puzzled me before I realized that it was really inserting 5000 rows. How can a single row insert get 60,000 buffers? It almost seemed like it was scanning the indexes or that there was something weird with the inline blob column. The top segments part of the AWR report pointed to the three indexes on this table and not to the blob segment so my guess was that somehow the index lookup had degraded into an index scan. But, when I finally realized that it was 5000 rows per execution then I divided the 60,000 buffer gets by 5000 rows to get 12 gets per inserted row. Given three indexes this didn’t seem crazy.

Hi Bobby,
Same thing with FORALL in PL/SQL (and with OCI-based drivers in general). There is only one (bulk) INSERT statement execution for many rows.
drop table t;
create table t(n number);
alter system flush shared_pool;
declare
lt_num sys.odcinumberlist := sys.odcinumberlist();
begin
lt_num.extend(1000);
for i in 1..1000 loop
lt_num(i) := i;
end loop;
forall i in 1..1000
insert into t values(lt_num(i));
end;
/
select sql_text, executions, rows_processed
from v$sql
where parsing_schema_name = user
and sql_text like ‘INSERT INTO T%’;
SQL_TEXT EXECUTIONS ROWS_PROCESSED
INSERT INTO T VALUES(:B1 ) 1 1000
Note that any BEFORE STATEMENT or AFTER STATEMENT triggers will fire only once per execution.
Thanks for your post. I will have to try your example when I get into work Monday.
I ran it and it worked like a charm.